Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Je crée des systèmes d'IA qui gèrent vos opérations commerciales
Niveau 2
Répond à des critères de performance élevés et a fait ses preuves en matière de satisfaction clients.
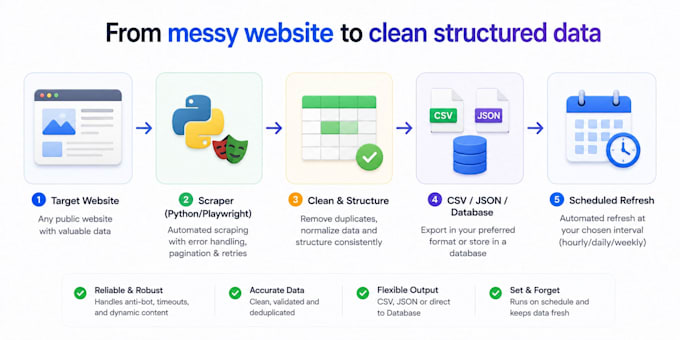
Vous avez besoin de données d’un site web mais les copier manuellement vous fait perdre du temps ? Je crée des scrapers Python et des bots d’automatisation de navigateur qui extraient des données propres et structurées en mode automatique.
Ce que je réalise :
Outils : Python, Scrapy, BeautifulSoup, Playwright, Selenium, Requests, curl_cffi, Pandas, services de proxy (Bright Data, ScraperAPI, ZenRows).
Je fournis du code prêt à l’emploi avec des instructions claires, pour que vous puissiez le relancer à tout moment, avec 7 jours de corrections gratuites.
Contactez-moi avec le site cible et les champs dont vous avez besoin.

Technologie:
Python
•
scrapy
•
sélénium
•
Beautiful Soup
•
Playwright
Technique:
Automatisé(e)
Traduction automatique
Est-ce légal / conforme ?
Je respecte les conditions d’utilisation des sites, le fichier robots.txt et les lois sur la vie privée. Je ne collecte pas de données personnelles sensibles ni ne contourne les paywalls. Je ne collecte que des données publiques ou professionnelles.
Pouvez-vous gérer des sites dynamiques, le défilement infini ou des pages rendues en JS ?
Oui, en utilisant Playwright/Selenium/Scrapy avec pagination, défilement, conditions d’attente et résilience face aux changements de layout.
De quoi avez-vous besoin pour commencer ?
URL(s) du site, champs à extraire, page(s) d’échantillon, volume attendu, format de sortie (CSV/Excel/JSON/Sheets/DB), et éventuellement identifiants de connexion ou de test si nécessaire.
Que faire face aux captchas, limites de taux ou blocages ?
J’utilise des proxies rotatifs, des user-agents, des stratégies de backoff/retries et une gestion intelligente du débit. En cas de forte anti-bot, je proposerai des alternatives sûres ou une couverture partielle.
Quels formats pouvez-vous livrer ?
CSV, Excel, JSON, Google Sheets ou chargement direct dans SQLite/PostgreSQL/MySQL. Je peux aussi fournir un schéma simple prêt pour l’ETL.
Incluez-vous le nettoyage et la validation des données ?
Oui, déduplication, nettoyage, conversion de types, parsing regex, et vérifications de cohérence pour l’exhaustivité ou l’unicité si applicable.
Vais-je recevoir le script de scraping ou seulement les données ?
Livraison des données basique/standard. La version Premium inclut le code Python + guide d’installation. La propriété du script vous sera transférée.
Pouvez-vous mettre en place un scraping ou une surveillance programmée ?
Oui, exécutions quotidiennes ou hebdomadaires avec mises à jour par email ou Sheets. La version Premium peut inclure un déploiement Docker ou un planificateur cloud léger.
Pouvez-vous extraire des données de n’importe quel site web ?
Je peux scraper la plupart des sites accessibles publiquement. Certains sites ont des conditions d’utilisation strictes ou nécessitent une connexion pour accéder à des données privées, ce que je signalerai avant de commencer. Je ne scrape que des données accessibles publiquement et je respecte les limites légales. Envoyez-moi l’URL cible et je confirmerai la faisabilité avant votre commande.