Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD


Traduction automatique
Je crée des pipelines de données OpenSearch qui gèrent les charges de travail en production, de la conception du schéma au déploiement sur AWS.
Ce que je propose
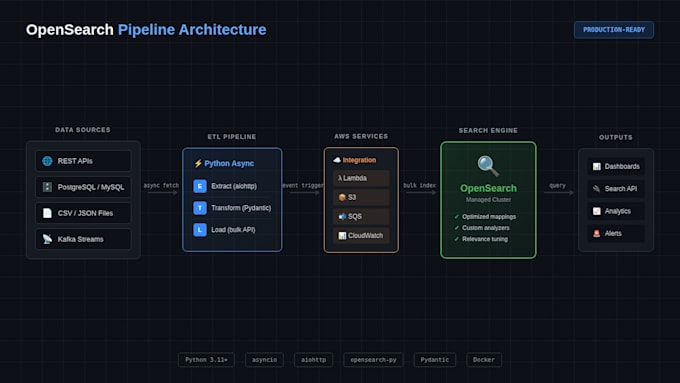
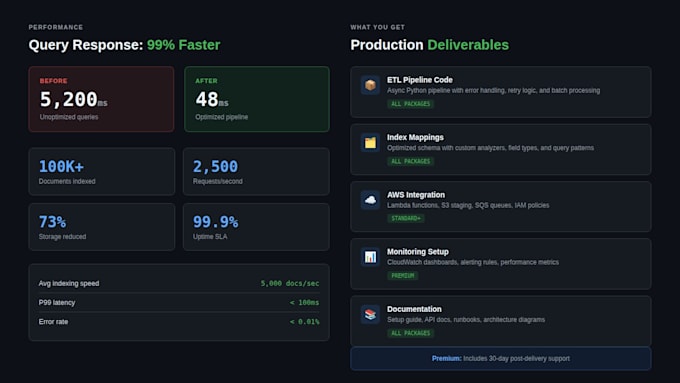
Ingestion de données : Pipelines ETL asynchrones utilisant Python (asyncio, aiohttp). Modes de traitement par lots et en temps réel. Support multi-source : API, bases de données, fichiers, flux.
Configuration OpenSearch : Mappings d’index optimisés pour vos modèles de requête. Analyseurs et tokenizers personnalisés. Réglage de la pertinence et requêtes d’agrégation.
Intégration AWS : Fonctions Lambda pour l’ingestion basée sur les événements. S3 pour le staging des données brutes. SQS/SNS pour le traitement par file d’attente. Déploiement sur Amazon OpenSearch Service.
Technologies :
Expérience :
Cas d’usage :
Avant de commander :
Python Backend Developer, AWS, Data Engineering
Langues
Traduction automatique
Traduction automatique
Je souhaite intégrer un moteur de recherche personnalisé à mon application web.
Excellent. Je peux utiliser OpenSearch pour stocker les documents indexés de vos articles, puis fournir des API pour gérer des requêtes complexes selon les besoins des utilisateurs. Je peux également générer des statistiques sur vos données et fournir des API pour alimenter un tableau de bord.
J'ai une application qui stocke des documents sur S3. Comment puis-je les indexer ?
Je peux configurer Amazon OpenSearch pour stocker vos documents indexés. Je peux utiliser un processeur par lots pour indexer les documents en masse ou déclencher une requête Lambda pour gérer les fichiers individuellement.
Je dois fournir des fonctionnalités de recherche basées sur des données textuelles. Pouvez-vous m'aider ?
Bien sûr. Je peux créer un pipeline qui ingère des données, provenant à la fois de la base de données principale et des flux de données, puis stocke efficacement ces données textuelles volumineuses dans OpenSearch. Je peux créer des requêtes complexes à exécuter sur des clusters OpenSearch et fournir des résultats classés par pertinence.
| (2) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |

bigfour98

Singapour
Quick to respond, polite, and display above-average understanding of opensearch
50 $US-100 $US
Prix
2 jours
Durée
coghan

États-Unis
Very professional. Great work
100 $US-200 $US
Prix
5 jours
Durée
| (2) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
bigfour98
Singapour
Quick to respond, polite, and display above-average understanding of opensearch
50 $US-100 $US
Prix
2 jours
Durée
coghan
États-Unis
Very professional. Great work
100 $US-200 $US
Prix
5 jours
Durée