Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD




Traduction automatique
Ingénieur senior ayant livré Axon, une SaaS multi-locataires avec Claude et OpenAI en production, utilisant un routage multi-LLM.
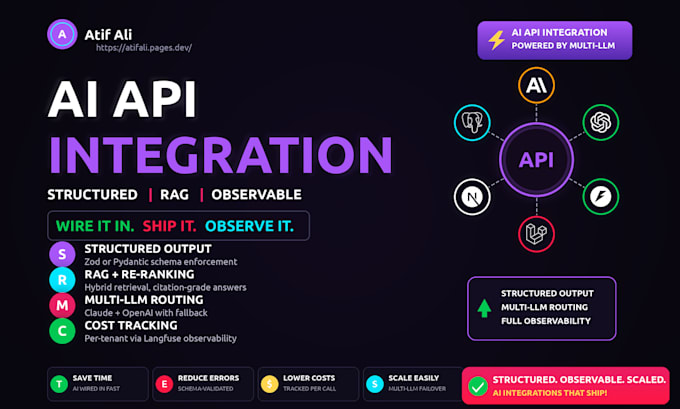
J’intègre les API d’IA dans votre application existante de la manière qui vous convient : sortie structurée avec validation stricte pour que les réponses échouent bruyamment en cas de malformation, réessais idempotents en cas de limite de débit ou de délai d’attente, ingénierie de prompt adaptée à votre domaine.
Une observabilité complète sur chaque appel pour que vous puissiez voir la latence, le coût et les résultats. Pipeline RAG avec récupération hybride, re-ranking et citations vers votre contenu réel.
Le niveau premium ajoute le routage multi-LLM avec fallback, le suivi des coûts par requête et la gestion des quotas par locataire.
Envoyez-moi votre stack et la fonctionnalité AI que vous souhaitez ; je m’occupe de l’intégration de bout en bout.
Senior FullStack Engineer Laravel, React, Python, Golang
Langues
Traduction automatique
Traduction automatique
Claude ou OpenAI, lequel choisir ?
Les deux sont supportés. Claude est plus performant pour le raisonnement sur de longs contextes, la sortie structurée et l'utilisation d'outils ; OpenAI est meilleur pour la génération de code et les tâches conversationnelles à faible latence. Je vous aide à choisir en fonction du cas d'usage, ou utilisez le routage multi-LLM avec le niveau Premium.
Qu'est-ce que RAG et pourquoi l'inclure ?
Retrieval-Augmented Generation ancre le LLM dans vos données au lieu de se baser uniquement sur sa coupure d'entraînement. Le niveau standard ajoute RAG sur vos documents pour que l'IA cite votre contenu réel, pas des réponses génériques.
Comment gérez-vous les coûts et les limites de taux ?
Le niveau premium inclut le suivi des coûts par requête (par tenant si multi-tenant), la limitation de taux par utilisateur et les retries idempotents en cas d'erreur de limite. Vous voyez exactement le coût de chaque appel AI et évitez les factures imprévues.
Signons-nous des NDA et protégeons-nous les clés API ?
Oui, NDA avant tout accès. Les clés API sont transmises via l'environnement d'exécution ou votre gestionnaire de secrets ; rien n'est stocké dans le dépôt ou l'image déployée. Je ne conserve pas les identifiants après la transmission.
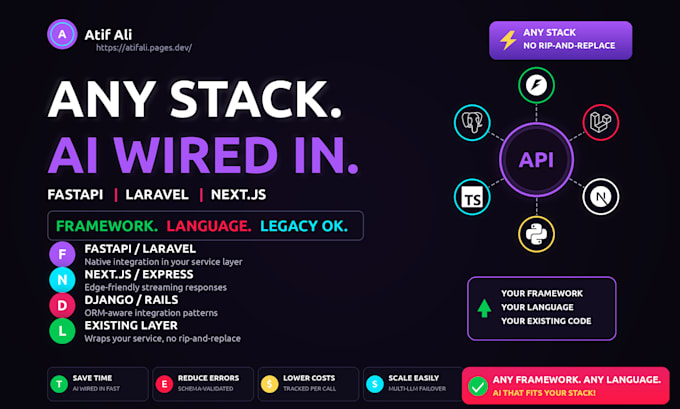
Avec quels stacks travaillez-vous ?
Laravel, FastAPI, Next.js, Express, Node.js, Django, Rails. L'intégration se fait via REST ou votre couche de service existante ; aucune modification majeure n'est nécessaire.