Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Inde
Ingénieur logiciel principal
Titre :
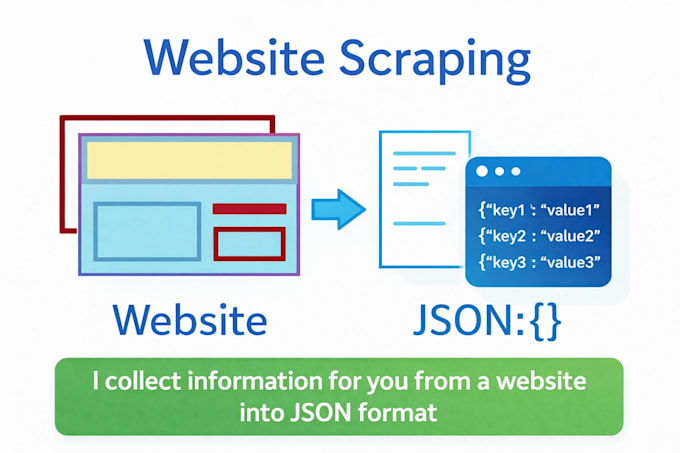
Je vais extraire des données JSON de qualité supérieure à partir de sites web (un modèle par source)
Vue d'ensemble :
Vous avez besoin de jeux de données JSON propres et structurés pour votre projet, recherche ou application ? Je me spécialise dans l'extraction web de haute qualité basée sur un seul modèle par source, fournissant des fichiers JSON validés prêts pour les API, bases de données ou analyses.
Contrairement aux extracteurs à bas coût en masse, je me concentre sur la précision, la validation et un formatage convivial pour les développeurs afin de garantir que vos données soient fiables et prêtes à la production.
Starter 100 $
Extraction jusqu'à 100 pages d'une source
Jusqu'à 5 champs
Fichier JSON validé
Livraison en 2 jours
Standard 200 $
Extraction jusqu'à 500 pages de 2 sources
Jusqu'à 10 champs par source
JSON imbriqué + nettoyage
Livraison en 4 jours
Premium 500 $
Extraction jusqu'à 2000 pages de 3 sources
Champs illimités
JSON prêt pour API + nettoyage avancé, rotation de proxy, gestion des erreurs
Livraison en 7 jours

Technologie:
C#
•
Python
•
Playwright
Type d'information:
Devise et actions
•
Sites Web
Technique:
Automatisé(e)
Traduction automatique
Fournissez-vous des scripts avec les données ?
Non, je ne livre que des jeux de données JSON propres et validés. Les scripts ne sont pas inclus dans cette service.
Et si le site bloque l'extraction ?
Pour les packages plus importants, j'utilise des techniques comme la rotation de proxy et la gestion des erreurs pour minimiser le blocage. Si un site est fortement protégé, je vous en informerai avant de commencer.
Quels types de sites pouvez-vous extraire ?
Je peux extraire la plupart des sites accessibles publiquement. Je n'extrais pas les sites nécessitant des identifiants de connexion, des données personnelles sensibles ou tout ce qui viole les politiques de Fiverr.
En quoi un modèle diffère-t-il d'une source ?
Une source peut être un hébergeur différent, tandis qu'une page peut suivre un modèle qui est important pour se concentrer sur les données. Une source peut avoir plusieurs pages basées sur des modèles nécessitant un effort supplémentaire et une configuration.