Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD

Level 2

Traduction automatique
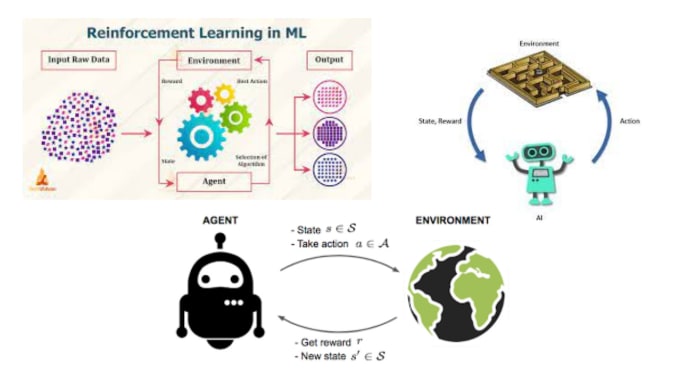
Agents de gradient de politique : exploitez la puissance des méthodes de gradient de politique, permettant à vos agents d'IA d'apprendre des politiques optimales grâce à l'ascension du gradient. Je me spécialise dans la conception, la formation et le réglage fin de ces agents pour diverses applications.
Deep Deterministic Policy Gradient (DDPG) : Profitez de DDPG, un algorithme de pointe pour les espaces d'action continue. Je peux vous aider à mettre en œuvre et à optimiser les agents DDPG pour des tâches telles que la robotique, les systèmes de contrôle et les véhicules autonomes.
Optimisation des politiques proximales (PPO) : PPO est connu pour sa stabilité et sa robustesse en RL. Je peux vous guider tout au long du processus d'utilisation de PPO pour former des agents dans des environnements complexes, garantissant une convergence rapide et des résultats de haute performance.
Architectures Acteur-Critique : Utilisez les méthodes Acteur-Critique pour les espaces d'action discrets et continus. Bénéficiez de la synergie de l'approximation de la fonction de valeur et de l'optimisation des politiques pour résoudre des problèmes RL complexes.
Intégration de réseaux neuronaux : exploitez la puissance des réseaux neuronaux profonds pour améliorer les capacités d'apprentissage de vos agents RL, en garantissant qu'ils s'adaptent et excellent dans des environnements complexes.
optimized AI Models
Level 2
Langues
Traduction automatique
