Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
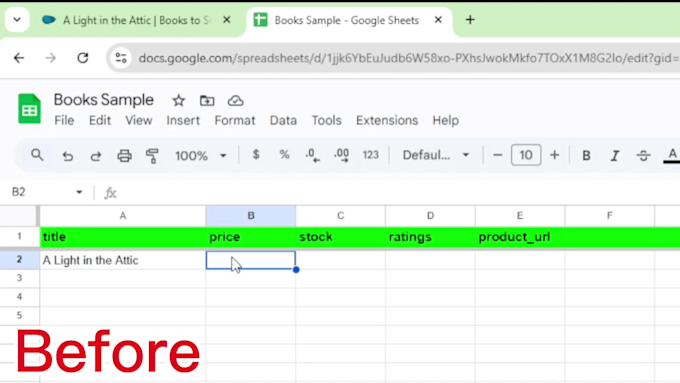
Python Web Scraping et automatisation
Web scraping et automatisation avec Python, données précises, code propre.
Je collecte des données structurées à partir de sites web (y compris JavaScript, défilement infini et pages login-only) et je les livre en CSV/Excel/JSON/Google Sheets. Besoin de produits e-commerce, d’annonces, de répertoires ou d’actualités ? Je suis là pour vous.
Ce que je propose
Limites : données publiques ou autorisées uniquement ; pas de contournement des paywalls ou 2FA. La protection renforcée peut nécessiter des proxies/CAPTCHA (tarification à l’avance).
Contactez-moi avec une URL d’exemple + les champs souhaités. Je confirmerai la faisabilité et vous proposerai le meilleur package.

Technologie:
Python
•
sélénium
•
Beautiful Soup
•
Playwright
•
Pandas
Technique:
Automatisé(e)
Traduction automatique
Pouvez-vous scraper des sites login-only ?
Oui — avec les identifiants fournis par le client et si les conditions d’utilisation le permettent.
Contournez-vous CAPTCHA/2FA ?
Non. Si un site utilise ces protections, je fournirai un devis pour les proxies/CAPTCHA et indiquerai les limites de fiabilité.
Le script se cassera-t-il si le site change ?
Les petites modifications dans les 7 jours sont gratuites ; pour des changements plus importants, je fournirai un devis.
Pouvez-vous pousser vers Google Sheets ou une base de données ?
Oui — API Sheets et export optionnel vers MongoDB.
Comment gérez-vous les sites dynamiques ?
Playwright/Selenium avec conditions d’attente, retries, et rythme compatible avec la limite de taux.