Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur en automatisation IA
Niveau 1
Répond à certains critères de performance et présente un fort potentiel sur la place de marché.
Très réactif
Connu(e) pour ses réponses exceptionnellement rapides
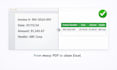
Vous copiez encore manuellement les données de factures ou PDF dans Excel ?
J’aide les entreprises à automatiser l’extraction de données de factures et de documents en utilisant Python, OCR et des workflows d’automatisation personnalisés, ce qui permet d’économiser des heures de travail répétitif.
Que vous ayez besoin d’extraire des données de factures, reçus, rapports, PDFs scannés ou documents professionnels, je peux convertir des fichiers désordonnés en fichiers Excel, CSV ou JSON propres et structurés.
Ce que j’extrais :
Comment ça fonctionne :
Formats de sortie : Excel, CSV, JSON
Pourquoi me choisir :
Prêt à arrêter la saisie manuelle de données ? Envoyez-moi vos besoins et je vous ferai une devis personnalisé en une heure.


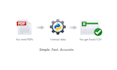

Technologie:
Excel
•
Python
•
Autres
Traduction automatique
Quels types de PDFs pouvez-vous traiter ?
Tout PDF contenant du texte – factures, relevés bancaires, rapports, contrats, formulaires ou documents scannés (OCR). Si vous pouvez voir les données, je peux les extraire. Envoyez-moi un exemple, je confirmerai en une heure.
Mes PDFs sont des images scannées, pouvez-vous quand même extraire les données ?
Oui. J’utilise l’OCR (Reconnaissance Optique de Caractères) pour lire le texte des PDFs scannés, photos ou documents basés sur des images. Le package Premium inclut la configuration complète de l’OCR. Le package Standard fonctionne pour les PDFs numériques ou basés sur du texte.
Quelle est la précision des données extraites ?
Plus de 99 % pour les PDFs numériques propres. Pour les documents scannés, la précision dépend de la qualité de l’image. Je vérifie toujours un échantillon avant le traitement complet et inclue une étape de revue. Vous approuvez avant la livraison finale.
Que faire si j'ai besoin de modifications après la livraison ?
Chaque package inclut des révisions (1 Basic, 2 Standard, 3 Premium). Les petits changements de mise en forme sont gratuits. Si vous souhaitez extraire d’autres champs ou traiter de nouveaux PDFs, c’est une nouvelle commande, mais je propose des remises pour les clients réguliers. Contactez-moi simplement.


