Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Analyste de données, ingénieur cloud data et expert en entrepôts de données
Niveau 1
Répond à certains critères de performance et présente un fort potentiel sur la place de marché.
Vous cherchez une solution fiable de pipeline de données qui maintient vos analyses à jour et précises ?
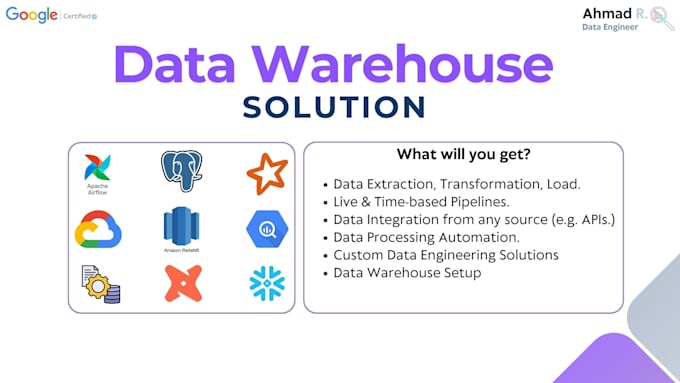
Je vais mettre en place des pipelines modernes d’ingénierie des données et des data warehouses sur Redshift, Google BigQuery, ClickHouse et Postgres.
Pipeline ETL/ELT par lot et architectures de streaming en temps réel, garantissant des flux de données fiables, automatisés et évolutifs pour l’analyse et les modèles AI/LLM.
Ce que vous obtenez :
Ma stack :
Pourquoi moi :
Ingénieur de données avec plus de 7 ans d’expérience. Je me spécialise dans Redshift, BigQuery, PostgreSQL et les architectures de data warehouse sur mesure.


Traduction automatique
Quelle est la différence entre pipelines ETL et ELT ?
ETL extrait, transforme puis charge les données ; ELT charge les données brutes puis les transforme dans le warehouse (courant avec BigQuery). Nous pouvons mettre en place l’un ou l’autre selon vos besoins.
Quel warehouse est le mieux pour moi ?
Redshift est idéal pour de gros workloads analytiques sur AWS. BigQuery est un warehouse GCP entièrement serverless pour des requêtes rapides et évolutives. PostgreSQL convient pour des données modérées et des requêtes SQL complexes. ClickHouse excelle en OLAP à haute vitesse et en analyses en temps réel. Le choix dépend de l’échelle de vos données et de votre cas d’usage.
Pouvez-vous gérer des données en streaming ?
Oui – je construis des pipelines en temps réel avec Kafka, Kinesis ou GCP Pub/Sub. Le streaming ETL est inclus dans le package Premium pour des flux de données à jour.
De quoi avez-vous besoin de ma part pour commencer ?
Veuillez fournir des détails sur vos sources de données (type, accès), le warehouse souhaité, un échantillon de données/schema, et vos objectifs de projet (rapports, utilisation ML). Cela permet d’adapter la solution.
Comment utilisez-vous l’IA dans le pipeline ?
J’utilise des outils d’IA pour automatiser certaines parties du workflow – par exemple, en utilisant GPT pour rédiger le code de transformation ou inférer le schéma de données, et en appliquant des modèles BigQuery ML/Redshift ML via SQL pour des fonctionnalités prédictives (si pertinent).