Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur logiciel
Entraînez votre LLM de codage avec des données DSA de qualité production, pas des clones de LeetCode scrappés
Je fournis un ensemble de données Python DSA original, de haute qualité, conçu spécifiquement pour l'entraînement, le fine-tuning et l'évaluation des LLM. Chaque problème est un exemple complet et autonome, pas seulement une question et une réponse.
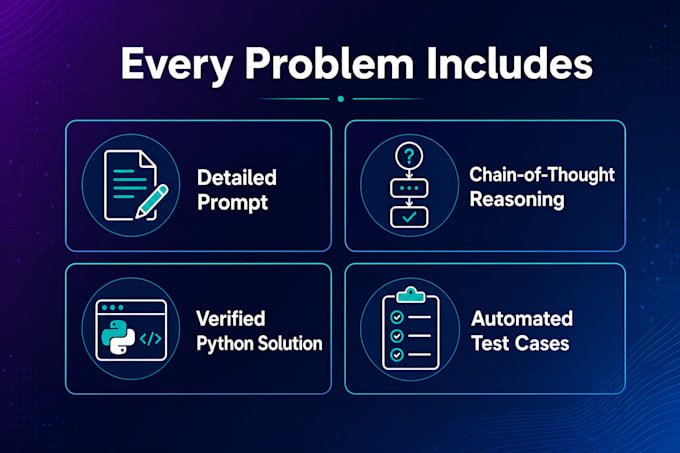
Plus de 855 problèmes de codage uniques, chacun comprenant :
ComponentDescriptionPrompt
Description détaillée du problème avec contraintes, spécifications d'entrée/sortie et règles de validation
Raisonnement
Chaîne de pensée étape par étape expliquant l'approche, le choix de l'algorithme et les cas limites
Solution
Implémentation Python fonctionnelle
Tests
Plusieurs cas de test avec assertions pour vérifier la correction
Ce qui distingue ce dataset
La plupart des datasets de codage en ligne sont :
Le mien est conçu pour l'entraînement AI dès le départ :




Traduction automatique
Est-ce scrappé de LeetCode ou HackerRank ?
Non. Chaque problème est original avec des scénarios, contraintes et cas de test uniques. Sûr pour l'entraînement commercial de LLM.
Sous quel format vais-je recevoir le contenu ?
Par défaut, les dossiers sont organisés par problème. Les versions Standard et Premium incluent JSONL. Indiquez-moi votre schéma et je l'adapterai.
Puis-je utiliser cela pour entraîner un LLM commercial ?
La version Premium inclut une licence d'utilisation commerciale. Les versions Basic et Standard sont destinées à l'évaluation et à la recherche, sauf accord contraire.
Chaque problème inclut-il un raisonnement en chaîne ?
Oui. Chaque problème possède un fichier de raisonnement dédié avec une explication étape par étape avant la solution.
Les solutions sont-elles vérifiées ?
Oui. Chaque problème comprend un fichier de test avec plusieurs assertions. Les solutions sont écrites pour passer tous les tests.
Puis-je demander des sujets spécifiques ?
Oui. Les versions Standard et Premium peuvent inclure des sous-ensembles filtrés par sujet (par exemple uniquement problèmes de graphes, uniquement DP).
Dans quelle langue sont les problèmes ?
Python. Les problèmes spécifient les signatures de fonction et l'I/O. Autres langues sur demande via commande personnalisée.
Puis-je voir un exemple avant d'acheter ?
Contactez-moi et je vous enverrai 2 à 3 problèmes d'exemple (caviardés) pour que vous puissiez évaluer la qualité.
Signez-vous des NDA ?
Oui. NDA et licence exclusive disponibles en option supplémentaire.
Créerez-vous de nouveaux problèmes pour mon cas d'utilisation ?
Oui. La création de problèmes personnalisés est disponible en option ou en service séparé.