Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
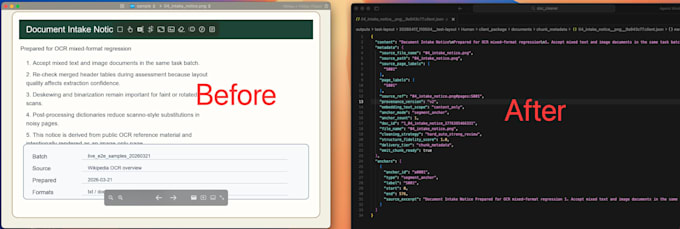
Développeur FullStack AI Freelance
Vous avez besoin de données de documents propres et fiables pour votre flux de travail AI ?
Je vous aide à transformer des documents simples en sorties prêtes pour RAG pour Dify, Make, Coze et des pipelines personnalisés.
Ce que vous obtenez
Idéal pour
Fichiers supportés
PDF, DOCX, PPTX, TXT, MD, PNG, JPG
Note importante sur le scope
Ce service n’est pas destiné à la reconstruction avancée de mise en page.
Si vos fichiers contiennent des tables fusionnées complexes, des en-têtes multi-lignes ou une mise en forme très complexe, contactez-moi d’abord pour une vérification préalable.
Note d’intégration
Je fournis des sorties nettoyées + des conseils/exemples d’utilisation.
Les scripts d’ingestion dans la base vectorielle sont côté client sauf si ajoutés en tant que commande personnalisée.


Convertir à partir de:
Convertir en:
JSON
Traduction automatique
Reproduisez-vous exactement la mise en page de tables complexes ?
Non. Il s’agit d’un service de nettoyage axé sur le texte et orienté RAG.
Pouvez-vous gérer des rapports complexes avec des cellules fusionnées ?
Généralement hors du scope pour ce service. Veuillez me contacter d’abord.
Intégrez-vous directement dans ma base vectorielle ?
Pas par défaut. Je fournis des sorties + conseils/exemples d’utilisation.
Que faire des fichiers TXT/MD sans numéros de page ?
J’utilise des ancres de segmentation virtuelles stables pour la traçabilité.