Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Bangladesh
Sur moi
Vous souhaitez construire un modèle d'apprentissage auto-supervisé (SSL) et découvrir des clusters significatifs dans vos données ?
- Vous êtes au bon endroit ! Je suis un expert en Deep Learning avec une expérience pratique en SSL, clustering et évaluation de tâches en aval.
Je peux travailler avec divers jeux de données d'images, notamment :
Pourquoi choisir mon service ?
Ce que je fournis :
Donnez vie à vos données ! Contactez-moi avant de commander pour vous assurer que vos besoins sont bien compris.



Expertise:
Traitement d'images
•
Classification
•
regroupement
Langage de programmation:
Python
•
Colab
•
Autres
Outils:
Jupyter Notebook
•
opencv
•
Colab
•
PyTorch
Frameworks:
PyTorch
•
Panda
•
Autres
Traduction automatique
Avec quels types d’ensembles de données pouvez-vous travailler ?
Je peux travailler avec tout type de jeu de données d'images, y compris des images médicales, des images satellites, des images de produits ou des jeux de données personnels/customisés.
Dois-je fournir un ensemble de données ?
Oui. si vous souhaitez que le modèle soit entraîné avec vos données (produits, visages, documents, etc.), vous devez fournir les images. Si vous n'avez pas de dataset, je peux vous aider à en collecter ou en trouver un moyennant un supplément. Contactez-moi d'abord !
Ai-je besoin de données étiquetées ?
Non, l'apprentissage auto-supervisé ne nécessite pas de données étiquetées. Cependant, des étiquettes peuvent être nécessaires si vous souhaitez une évaluation sur une tâche en aval (packages Standard & Premium).
Y a-t-il des limitations concernant la taille du jeu de données ?
Je travaille généralement avec des jeux de données qui tiennent dans la mémoire GPU disponible, comme Colab et Kaggle GPU. Pour des jeux de données très volumineux, nous pouvons utiliser des stratégies telles que l’échantillonnage, le batching ou le traitement distribué.
Quels modèles d'apprentissage profond utilisez-vous ?
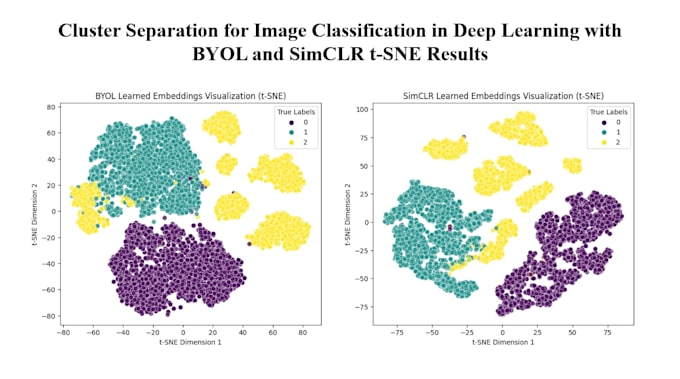
J’utilise des modèles d'apprentissage auto-supervisé de pointe tels que SimCLR, BYOL, Barlow Twins.
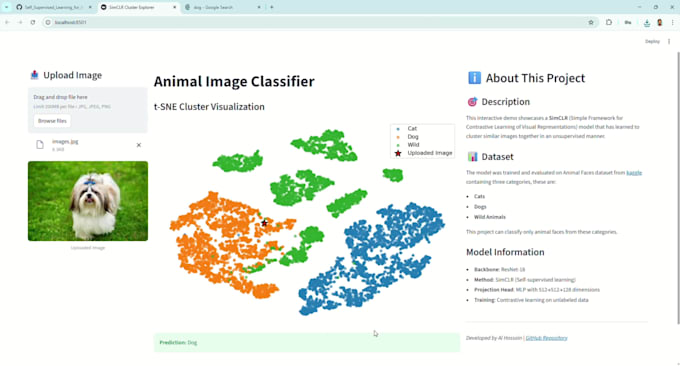
Pourrai-je utiliser facilement le modèle ?
Absolument ! Pour le package Premium, je fournis une application web Streamlit conviviale pour explorer interactif les clusters et tester les tâches en aval.
Pouvez-vous évaluer la performance du modèle ?
Oui, je fournis des métriques d’évaluation détaillées sur les tâches en aval, y compris la précision, la perte et des visualisations des clusters.
Garantissez-vous la confidentialité ?
Oui, complètement. Vos données et détails de projet sont gardés strictement confidentiels.