Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Automatisation, Web scraping Django, Flask, développement web frontend InstagramAnalyst
Niveau 1
Répond à certains critères de performance et présente un fort potentiel sur la place de marché.
Bonjour,
Vous avez besoin d'extraire rapidement et proprement des données d'un site web ? Je crée des web scrapers Python personnalisés utilisant BeautifulSoup, Selenium, Playwright et Scrapy pour une extraction précise et automatisée de données depuis n'importe quel site public.
Je propose des services d'extraction de données et de web scraping en Python de niveau expert en utilisant des outils reconnus dans l'industrie comme :
️ Outils de scraping que j'utilise :
Fonctionnalités & Résultats :
Je ne scrape que des sources de données accessibles légalement et publiques.
Contactez-moi avant de commander pour discuter de votre cas d'utilisation. Je suis prêt à vous aider à automatiser et extraire les données web dont vous avez besoin.
almohid

Traduction automatique
Qu’est-ce que le web scraping et comment peut-il bénéficier à mon entreprise ?
Le web scraping consiste à extraire automatiquement des données de sites web. Cela permet aux entreprises de collecter des données structurées précieuses pour la recherche de marché, l'analyse de la concurrence, la surveillance des prix, la génération de leads, l'agrégation de données produits et le suivi des tendances, le tout sans effort manuel.
Quels types de sites pouvez-vous scraper avec Python ?
Je scrape une large gamme de sites, y compris des boutiques en ligne, des portails d'emploi, des annonces immobilières, des annuaires d'entreprises locales, des portails d'actualités, des bases de données académiques, et plus encore. *Note : Vérifiez toujours les permissions du site avant de scraper
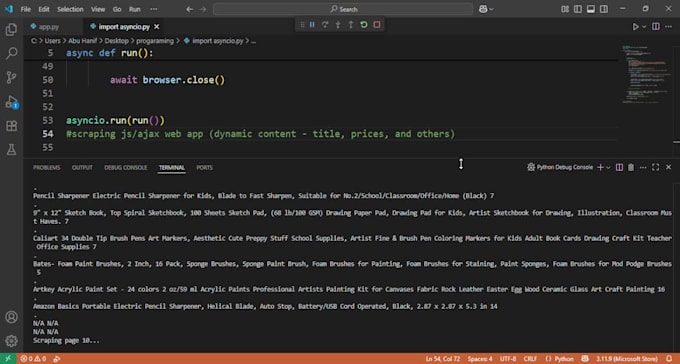
Pouvez-vous scraper des sites utilisant beaucoup de JavaScript ou un chargement dynamique ?
Absolument ! En utilisant Playwright et Selenium, je gère des pages web complexes avec un chargement dynamique via AJAX, défilement infini ou d'autres éléments pilotés par JavaScript, en veillant à ne manquer aucune donnée.
Comment gérez-vous les sites nécessitant une connexion ou une authentification de session ?
J'automatise les processus de connexion sécurisée avec Playwright ou Selenium, en gérant cookies et jetons de session pour extraire les données derrière des murs de connexion, en conformité totale avec les termes et conditions du site.
Dans quels formats puis-je recevoir mes données scrappées ?
Je fournis des données propres et validées dans des formats tels que CSV, Excel, JSON, XML, bases de données SQL ou Google Sheets, adaptés à votre flux de travail ou à vos besoins d'intégration système.
Fournissez-vous les scripts de scraping et le code d'automatisation ?
Oui ! Sur demande, je partage des scripts Python entièrement commentés et réutilisables, construits avec Playwright, Selenium ou Scrapy, vous permettant de lancer ou de personnaliser le scraper de manière autonome.
Pouvez-vous mettre en place des tâches de scraping planifiées et automatisées ?
Certainement. Je configure des cron jobs, des fonctions cloud ou des scrapers sans serveur pour qu'ils s'exécutent automatiquement à des intervalles personnalisés — quotidien, hebdomadaire ou mensuel — pour un rafraîchissement continu des données.
Comment gérez-vous les protections anti-scraping et la détection de bots ?
J'emploie des techniques avancées incluant rotation d'user-agent, utilisation de proxy, modes furtifs du navigateur (notamment avec Playwright), throttling des requêtes et gestion CAPTCHA (là où c'est permis) pour contourner éthiquement les mesures anti-bot courantes.
À quelle vitesse puis-je recevoir mes données scrappées ?
Le délai dépend de la complexité : les tâches simples prennent généralement 1 à 3 jours ; les projets de crawling multi-pages ou à grande échelle prennent entre 3 et 7 jours. Je fournis des délais clairs et transparents avant de commencer.