Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur Data, AWS, Apache Airflow, Spark, PostgreSQL, ETL
Vous êtes submergé par des données brutes sans moyen fiable de les traiter ?
Je crée des pipelines de données de niveau production qui s'exécutent automatiquement, évoluent avec vos données et ne se cassent jamais silencieusement. Pas de scripts spaghetti. Pas d'étapes manuelles. Juste des données propres et fiables exactement où vous en avez besoin.
Ce que je construis
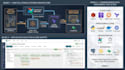

Traduction automatique
Q : De quelles informations avez-vous besoin pour commencer ?
R : Votre source de données (S3, API, base de données, CSV), votre destination cible, les exigences de transformation, et la fréquence d'exécution du pipeline.
Q : Pouvez-vous travailler avec mon infrastructure existante ?
R : Oui. Envoyez-moi les détails et j’évaluerai la compatibilité avant de commencer.
Q : Ai-je besoin d’un compte AWS ?
R : Pour un travail basé sur AWS, oui — vous aurez besoin de votre propre compte. Je peux vous guider dans la configuration si nécessaire.
Q : Posséderai-je le code ?
R : Tout à fait. Tout le code source vous sera remis à la livraison.
Q : Pouvez-vous gérer de grands ensembles de données ?
R : Oui. J’utilise PySpark et EMR sur EKS car ils sont conçus pour le traitement de données à grande échelle.
Q : Que faire si quelque chose ne fonctionne plus après la livraison ?
R : Je propose un support après livraison. Contactez-moi et je corrigerai si besoin.


