Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur en données et intelligence artificielle !
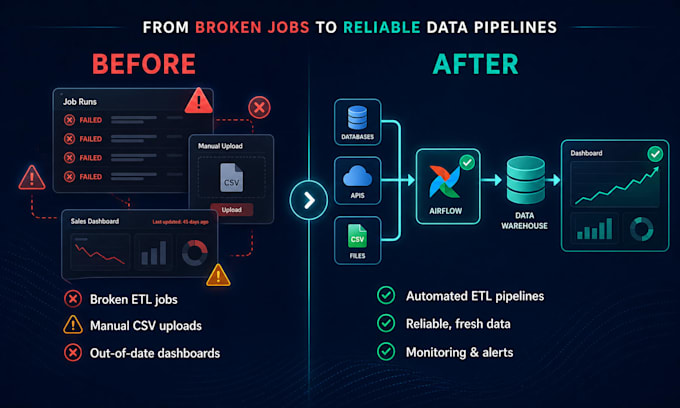
Vos rapports et tableaux de bord ne sont aussi bons que le pipeline qui les alimente. Je conçois et répare des pipelines ETL qui déplacent les données de vos bases d'applications ou API vers BigQuery, Snowflake ou Azure SQL, afin que vos outils de BI et modèles d'IA disposent toujours de données fraîches et fiables.
Je suis ingénieur en Data & AI. J'ai construit et réparé des pipelines pour des entreprises qui avaient besoin de rapports quotidiens fiables, plutôt que de scripts cassés ou de travail manuel sur Excel. Si vos tâches de traitement de données échouent constamment, sont lentes ou si vos tableaux de bord ne reflètent pas la réalité, je vais en identifier la cause principale.
Je peux vous aider :
Stack technique : Python, SQL, Postgres, MySQL, SQL Server, BigQuery, Azure, Snowflake, Airflow, Fabric.
Comment ça marche
Contactez-moi avant de commander pour que nous discutions du problème et de la façon dont je vais le résoudre.


Traduction automatique
Dois-je vous envoyer un message avant de commander ?
Oui. Une discussion rapide m'aide à comprendre vos sources de données, outils et délais pour confirmer la portée et suggérer le bon package.
De quel accès avez-vous besoin ?
Généralement, accès en lecture aux sources de données, accès en écriture à la cible (DB/entrepôt/feuilles), et un environnement de test lorsque c'est possible. Nous pouvons aussi travailler avec des données d'exemple si l'accès complet n'est pas autorisé.
Pouvez-vous travailler avec mes scripts/pipelines existants ?
Oui. Je peux examiner votre configuration actuelle, corriger les problèmes et nettoyer les choses plutôt que de tout reconstruire à partir de zéro.