Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Extraction de données à partir de PDFs, portails gouvernementaux et documents scannés
Vous avez un PDF rempli de données inutilisables ? Je le transformerai en une feuille de calcul propre et structurée.
Je me spécialise dans les cas difficiles - documents scannés, PDFs basés sur des images, dépôts gouvernementaux, rapports financiers, factures, et toute source résistante au copier-coller.
Ce que vous obtenez :
Mes outils : Python, Pandas, OCR alimenté par IA, outils modernes d’IA
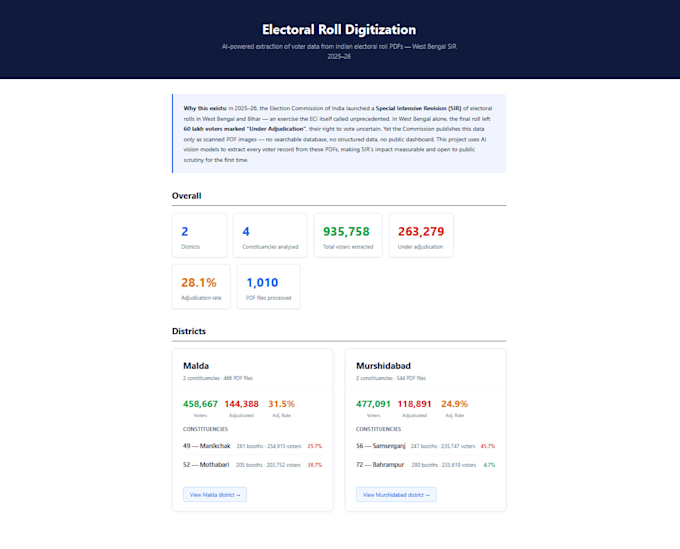
Mon expérience : J’ai extrait 1,28 million d’enregistrements à partir de PDFs de listes électorales scannés pour AltNews, l’une des principales organisations de vérification des faits en Inde. Si je peux extraire des données d’électeurs de documents gouvernementaux uniquement en image derrière des CAPTCHAs, je peux gérer vos PDFs.
Envoyez-moi un PDF d’échantillon avant de commander - je vous dirai exactement ce que je peux livrer et à quelle vitesse.

Technologie:
Python
•
Excel
•
sélénium
•
Beautiful Soup
•
Pandas
Technique:
Automatisé(e)
Traduction automatique
Quels types de PDFs pouvez-vous traiter ?
PDF natifs, PDFs scannés uniquement en image, documents gouvernementaux, rapports financiers, factures et listes. Si du texte ou des chiffres sont visibles à l’œil, je peux les extraire. Envoyez un échantillon d’abord, je confirmerai la compatibilité et le délai dans la journée.
Dans quel format recevrai-je les données ?
Excel (.xlsx), CSV ou Google Sheets - à votre choix. Je peux aussi fournir du JSON pour des données structurées ou imbriquées. Indiquez votre préférence lors de la commande, ou je prendrai par défaut un Excel propre avec un onglet par source.
Traitez-vous des PDFs non anglophones ?
Oui. J’ai une expérience particulière avec des documents en hindi et bengali, y compris scannés. La plupart des langues utilisant l’alphabet latin fonctionnent également bien. Si votre source est dans un autre script (arabe, tamoul, etc.), envoyez un échantillon d’abord - je confirmerai la capacité avant votre commande.