Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
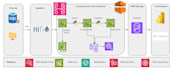
Ingénierie des données, Azure, AWS, Databricks, Lakehouse, Spark, Fabric
Vos données AWS sont-elles cloisonnées, peu optimisées ou en train d'augmenter vos coûts ?
En tant que Senior Data Engineer avec 9 ans d'expérience, je conçois des pipelines ETL AWS de qualité production, automatisés, économiques et évolutifs. Je me spécialise dans la transformation de données fragmentées S3 en actifs structurés et performants pour l’analyse et l’IA.
Ce que je vous propose :
Pourquoi choisir ce service ?
Je ne me contente pas d’écrire des scripts ; je construis des architectures. Chaque pipeline que je livre est conçu pour être sans serveur, ce qui réduit votre facture AWS mensuelle tout en maximisant le débit. De la logique d’archivage S3 à l’alerte automatisée, je veille à ce que vos données soient gouvernées et fiables.
Prêt à optimiser votre stack de données AWS ? Construisons ensemble un pipeline évolutif


Traduction automatique
Quels services AWS utilisez-vous pour les pipelines ETL ?
J’utilise AWS Glue, S3, Redshift, IAM, CloudWatch et Spark selon les besoins du projet.
Pouvez-vous construire à la fois des pipelines batch et incrémentaux ?
Oui, je conçois à la fois des pipelines batch et incrémentaux en fonction du volume de données et des exigences de latence.
Gérez-vous la validation de la qualité des données ?
Oui, je mets en place des vérifications de validation, l’application de schémas et la détection d’anomalies.
Pouvez-vous optimiser les pipelines AWS existants ?
Absolument. J’optimise la performance, le coût et la fiabilité.
Fournirez-vous une documentation ?
Oui, une documentation technique complète et une passation.
Supportez-vous l’ingestion de données via API ?
Oui, via REST APIs, bases de données et sources de fichiers.
Pouvez-vous construire des pipelines CI/CD ?
Oui, sur demande.
La sécurité est-elle prise en charge ?
Oui, rôles IAM, chiffrement et contrôles d’accès.
Supportez-vous les pipelines en temps réel ?
Oui, en utilisant Kafka / Kinesis si nécessaire.
Proposez-vous une assistance post-livraison ?
Oui, je fournis un support après la livraison.


