Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Données et logiciels
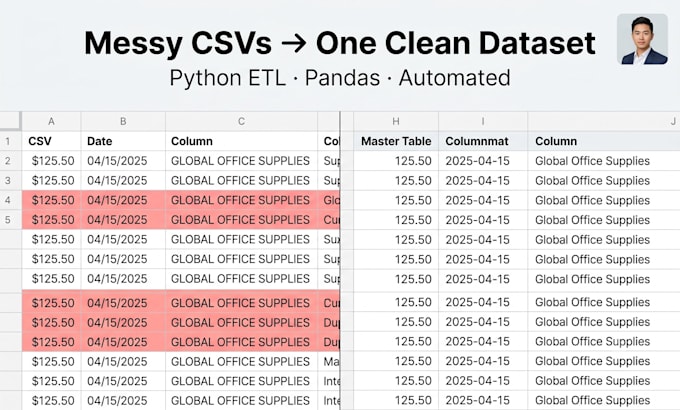
Avez-vous des feuilles de calcul provenant de différentes équipes, outils ou départements, chacune avec des noms de colonnes différents, des formats de date variés, des doublons et des valeurs incorrectes ? Les nettoyer et les fusionner manuellement est lent et sujet à erreur. Je vais automatiser tout cela avec Python + Pandas.
Ce que je fais
Je construis un flux de travail ETL réutilisable qui :
Ce que vous obtenez
Pourquoi me choisir


Traduction automatique
Le script fonctionnera-t-il aussi sur les fichiers du mois prochain ?
Oui — Les packages Standard et Premium fournissent un script réutilisable qui gère les fichiers avec la même structure, vous pouvez donc le relancer à tout moment sans coder.
Mes fichiers ont des noms de colonnes différents — est-ce un problème ?
Pas du tout. La cartographie des champs vers un schéma standard unique fait partie intégrante du service.