Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
À propos de cette service
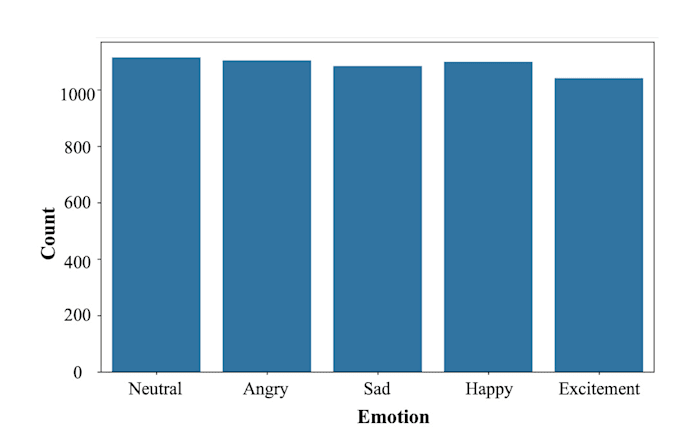
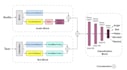
Je me spécialise dans la création de systèmes de reconnaissance vocale et émotionnelle multimodaux en combinant les modalités audio et texte pour une performance et une précision accrues.
Fort d'une expérience pratique sur des ensembles de données complexes comme IEMOCAP et MELD, j'ai développé des modèles hybrides personnalisés utilisant Bi-LSTM et CNN, atteignant jusqu'à 85 % de précision sur l'ensemble de données IEMOCAP. Je explore également activement Word2Vec et les architectures basées sur Transformer pour une meilleure compréhension contextuelle dans la parole.
Vous pouvez consulter mes projets et articles de recherche liés ci-dessous pour plus de détails.
Ce que je propose :
N'hésitez pas à m'envoyer un message avant de passer commande pour discuter de vos besoins spécifiques.

Expertise:
Classification
•
Discours & Audio
•
Analyse prédictive
Langage de programmation:
Python
•
Colab
APIs:
Autres
Outils:
Jupyter Notebook
•
Amazon SageMaker
•
Colab
Frameworks:
Scikit-learn
•
keras
•
PyTorch
•
Panda
•
tensorflow