Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Pays-Bas
Ingénieur de données Azure
Vous cherchez un ingénieur de données Azure fiable pour créer des pipelines ETL évolutifs ou migrer vos données efficacement ?
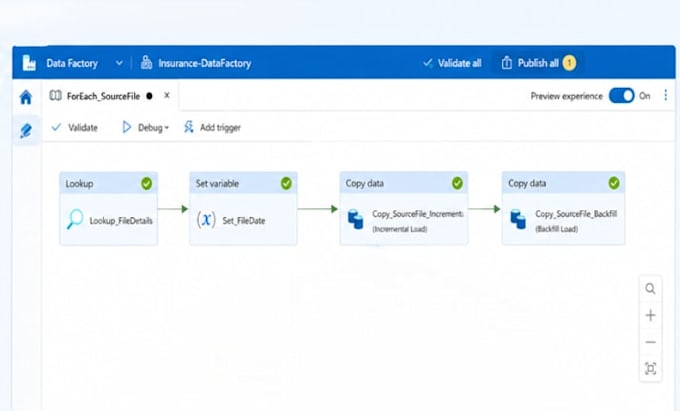
Je me spécialise dans la conception et le développement de pipelines de données de bout en bout en utilisant Azure Data Factory, Databricks (PySpark) et Azure Data Lake (ADLS).
Voici ce que je peux faire pour vous :
Pourquoi me choisir ?
Outils & Technologies :
Azure Data Factory | Databricks | PySpark | ADLS | SQL
Veuillez me contacter avant de passer commande pour discuter de vos besoins et garantir la meilleure solution.
Construisons ensemble un pipeline de données robuste et efficace pour votre entreprise

Outils et plateformes:
AWS Glue DataBrew
•
Azure Data Factory
Traduction automatique
De quelles informations avez-vous besoin pour démarrer le projet ?
J'ai besoin de détails sur votre source de données (SQL, API, fichiers), le système cible (ADLS, Salesforce, etc.), les exigences de transformation et les identifiants d’accès (si applicable). Nous pouvons également tout discuter avant de commencer.
Pouvez-vous construire des pipelines Azure de bout en bout ?
Oui, je conçois des pipelines ETL complets en utilisant Azure Data Factory, Databricks (PySpark) et ADLS, incluant ingestion, transformation et validation.
Supportez-vous le chargement incrémental ou les pipelines CDC ?
Oui, je peux mettre en place des chargements incrémentaux et des pipelines basés sur CDC pour traiter efficacement uniquement les données nouvelles ou modifiées.
Que faire si j'ai besoin de modifications après la livraison ?
Je propose des révisions selon le package choisi. Les modifications mineures sont incluses, tandis que les exigences supplémentaires peuvent être traitées séparément.
Fournissez-vous de la documentation?
Oui, je fournis une documentation claire et peux expliquer le pipeline pour que vous puissiez le gérer facilement à l'avenir.
Dois-je vous contacter avant de passer une commande ?
Oui, je recommande de discuter d’abord de vos besoins pour assurer la meilleure approche et éviter tout malentendu.
