Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD

Backend and Data Engineer building scalable APIs databases and ETL systems
Compétences
Voir mes services

Freelancing Career
8 mos
University Management System (UMS) — Production REST API
Jan 2026 - May 2026 • 4 mos
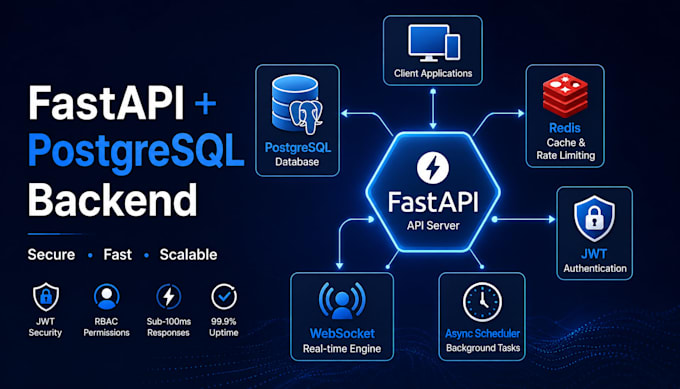
Built solo: fully deployed university backend — 3 isolated PG16 dbs, 25 schemas, 240+ tables, 24 API domains, 117-role RBAC. Zero plaintext creds on disk. Security AES-256-GCM vault (scrypt KDF) stores DSNs, JWT keys, Redis pw, RBAC — decrypted at startup, RAM-wiped (os.urandom+gc.collect()). Every conn validated via pgcrypto.crypt(). 11-step middleware: JWT decode → device bind → IP bind (SHA-256) → asyncio.gather(Redis blacklist + session cache) → per-table perms. Blacklist TTL = remaining token lifetime; device/IP binding togglable via Redis app_settings runtime. Architecture 3 DBs: auth_db (identity, MFA, 117-role enum, RANGE-partitioned audit 2025-2035), uni_db (22 schemas), portfolio_db (public + GDPR). View-first: all reads via auto-generated vw_ views — zero N+1, zero base-table reads from route handlers. generate_routes.py builds read/upsert/delete per domain; generate_uni_db_views.py produces 250+ views from introspection. 4,500+ alias map entries resolve URL → schema.table for real-time perms. 6 SlowAPI rate limiters (read/write per DB) — IP-keyed for reads, user-ID for writes, Redis-backed after startup. DB Engineering pg_trgm+unaccent search, CITEXT, UUID PKs, JSONB, pgcrypto. asyncpg pools with per-connection setup callbacks injecting handshake tokens. 25 Schemas person · core · admissions · SIS · LMS · exams · faculty · HR · finance · library · research · alumni · hostel · transport · communication · complaints · health · CMS · sports · placement · legal · admin Stack Python 3.12 · FastAPI 0.115 · PG16 · asyncpg 0.29 · Redis 7 · Pydantic v2 · Uvicorn/Gunicorn · AES-256-GCM · scrypt · bcrypt(cost12) · SlowAPI · python-jose · Starlette · OpenAPI · GZip Skills:- Database Design Identity and Access Management (IAM) Software as a Service (SaaS) Cybersecurity REST APIs Redis Database Architecture FastAPI Software Architecture Data Engineering Python (Programming Language) Microservices PostgreSQL Role-Based Access Control (RBAC)
Real-Time MT5 Brokerage Data Platform & Analytics API
Jan 2025 - Apr 2025 • 3 mos
Multi-tenant FastAPI backend serving 10,000+ MetaTrader5 + MyFxBook users at sub-100ms latency. Each tenant runs a dedicated RAM-resident SQLite DB (Fernet-encrypted at rest), with background sync process keeping API thread unblocked. Architecture Per-tenant SQLite DBs — never shared tables. Fernet-encrypted .enc files on disk, full decryption into RAM at boot; disk stays encrypted. Read/write split via .backup() API — dashboard reads never block sync writes. Fully async (httpx+asyncio) with separate data_updater.py process — zero blocking on request thread. Credentials decrypted only inside MT5/MyFxBook login calls, immediately scoped — never logged/cached. 3-Cycle Pipeline Every 5min: M1+D1 OHLCV for EUR/USD, GBP/USD, USD/JPY, USD/CHF, EUR/JPY, GBP/JPY via shared dummy MT5 account. Every hour: JWT refresh for active users. Daily 00:00 UTC: sync history_orders, history_deals, account_details + HPR-compounded gain recalculation for both MT5 & MyFxBook. Financial Engine HPR compound gain: chronological deal walk → daily return vs balance → auditable cumulative %. Stateless margin/profit calculators wrapping MT5's native functions. Deposit/withdrawal aggregation via comment-pattern filtering — consistent across brokers. Security Fernet (AES-128-CBC + HMAC-SHA256) encrypts credentials + DBs at rest. JWT role-gated routes (user/admin); admin endpoints return 403. Stack Python · FastAPI · MT5 SDK · MyFxBook REST · SQLite3 (WAL) · Fernet · httpx · asyncio · PyJWT · Uvicorn Skills:- Database Design Software as a Service (SaaS) Cybersecurity REST APIs Database Architecture Extract, Transform, Load (ETL) FastAPI Software Architecture Data Engineering Algorithmic Trading Python (Programming Language) Financial Analysis FinTech SQLite Role-Based Access Control (RBAC)
PubMed Biomedical Data Lake & NLP Enrichment Pipeline — 2,000,000+ Papers, Solo in ~2 Weeks
Sep 2024 - Oct 2024 • 1 mo
ault-tolerant ETL system built solo in ~2 weeks: processes 7GB/2M+ PubMed papers into NLP-enriched, query-ready Apache Parquet data lake — runs unattended on commodity hardware with full crash recovery & zero duplicate output on restart. Pipeline — 3 Idempotent Scripts main.py: recursive discovery → multiprocessing.Pool → regex parsing into 17 sections → memory-bounded batch Parquet writes + move-on-success. add_search_keywords.py: NLTK tokenization → 942-term curated biomedical stopword filter → keyword enrichment. combine_parquet.py: row-group streaming merge via PyArrow — no full in-memory load regardless of size. Fault Tolerance Ledger dedup: reads only file_name column (partial Parquet) at startup — skips already-processed. Move-on-success: raw/ → processed/ after confirmed write — crash recovery = re-run, not reprocess. Chunk-then-consolidate: shards to temp_parquet_chunks/, merged to canonical only after full batch succeeds — no partial corruption. Fixed-size batching = memory bounded by batch, not corpus. Parsing Engine txt_data_analyzer.py surfaces lines repeating ≥3x as structural markers → became 17 hard-coded header regex patterns. Applied per-file across 2M+ heterogeneous docs for consistent schema. NLP Enrichment 942-term hand-curated biomedical stopwords (preserves clinical terms generic lists strip). Linguistic quality scoring via english_word_count.py cross-referencing NLTK English corpus. QA Toolkit (7 scripts) txt_data_analyzer · word_count · char_count · english_word_count · pdf_txt (PyMuPDF batch) · pdf_word (PDF→DOCX) · data_format_converter (CSV↔JSON↔XLSX↔XML↔SQL↔SQLite) Stack Python 3 · pandas · PyArrow · Parquet(Snappy) · multiprocessing · re · NLTK · PyMuPDF · PyPDF2 · python-docx · SQLite3 Skills:- Database Design Data Lakes Text Mining Software as a Service (SaaS) Database Architecture Extract, Transform, Load (ETL) Big Data Software Architecture Data Warehousing Data Engineering Python (Programming Lan
