Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Inde
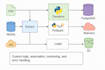
Du chaos des données à la clarté, fait correctement dès la première fois
Vous avez du mal avec des données désordonnées ou vous avez du mal à transférer des données entre différents systèmes ?
Laissez-moi vous aider avec un pipeline ETL propre, efficace et évolutif utilisant Python ou PySpark.
Je suis ingénieur data avec plus de 5 ans d’expérience dans la création de pipelines de données robustes, le nettoyage de millions d’enregistrements et l’automatisation de workflows pour des startups, des entreprises et des produits SaaS.
Ce que je propose :
Outils & Technologies :


Traduction automatique
De quoi avez-vous besoin de ma part pour commencer ?
J’aurai besoin de détails comme votre source de données (CSV, base de données, API, etc.), plateforme de destination, exemple de données (si disponible), règles de transformation, et toute exigence de planification ou d’orchestration.
Pouvez-vous vous connecter à des bases de données cloud ou des APIs ?
Oui ! Je peux me connecter à des plateformes cloud comme AWS RDS, Google BigQuery, PostgreSQL, S3, et APIs en utilisant Python ou PySpark.
Proposez-vous une planification ou une automatisation pour le pipeline ?
Absolument. Je peux configurer des tâches cron ou des DAG Airflow selon votre environnement et le choix du package.
Gérez-vous des données en temps réel ou en streaming ?
Oui, dans le package Premium ou en option, je peux mettre en place des pipelines de streaming avec Kafka, Apache NiFi ou des outils similaires.
Le code sera-t-il réutilisable et documenté ?
Oui, chaque package inclut une documentation claire. Les packages Standard et Premium comprennent des fichiers README structurés, des instructions de configuration et même des diagrammes de flux.
Et si je ne connais pas encore la logique de transformation exacte ?
Pas de souci ! Je peux vous aider à la définir en fonction de votre cas d’usage et vous guider pour affiner votre logique avant le développement.
Puis-je obtenir des révisions si quelque chose ne fonctionne pas comme prévu ?
Certainement. Chaque package inclut des révisions, et vous pouvez en ajouter si nécessaire. Je vise la pleine satisfaction.


