Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD



Traduction automatique
J'annoterai vos images et entraînerai un modèle YOLO personnalisé qui détecte VOS objets, pas des démonstrations génériques pré-entraînées.
Je suis membre de NVIDIA Inception avec une équipe d'IA/ML en Python qui a déployé des systèmes de détection d'objets dans la fabrication, la sécurité, la restauration et l'analyse sportive dans 6 pays.
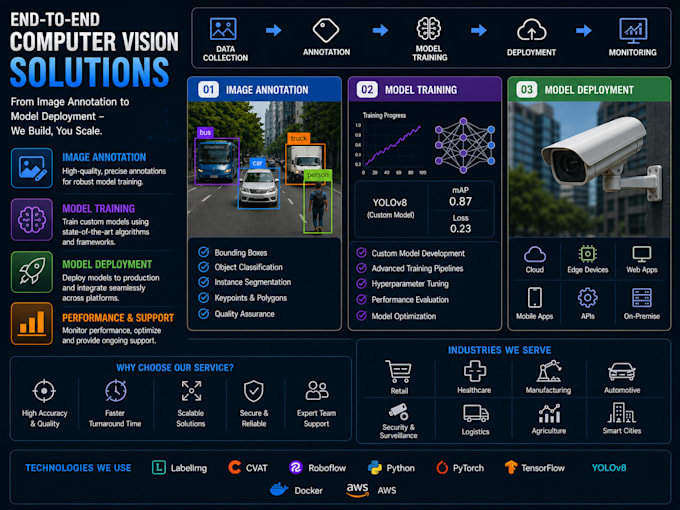
CE QUE JE FOURNIS :
ÉTAPE 1 ANNOTATION & ÉTIQUETAGE
Annotation par boîte englobante, polygone ou point clé
Outils : CVAT, LabelImg, Roboflow, Label Studio, export au format YOLO (yaml + labels txt)
ÉTAPE 2 PRÉPARATION DU dataset
Augmentation, division en train/val/test, audit de qualité
ÉTAPE 3 ENTRAÎNEMENT DU MODÈLE YOLO
Entraînement personnalisé YOLOv8 sur votre dataset, accéléré par GPU avec CUDA NVIDIA, rapport mAP, précision, rappel et matrice de confusion
ÉTAPE 4 DÉPLOIEMENT (offre premium uniquement)
Optimisation TensorRT, inférence 3-5x plus rapide, endpoint d'inférence FastAPI, script Python prêt à l'emploi
CE QUE J'AI RÉALISÉ :
Suivi de joueurs de football en temps réel pour 22 joueurs
Détection de fumée et EPI sur hardware NVIDIA Jetson
Contrôle de conformité à l'hygiène en cuisine de restaurant
Vous recevez : dataset étiqueté, poids du modèle entraîné, script d'inférence et rapport d'entraînement.
Contactez-moi avant de commander avec vos images et votre cas d'utilisation.
AI App Development Expert, Computer Vision, OpenCV, Object Detection
Langues
Traduction automatique
Traduction automatique
Quels formats d'images acceptez-vous ?
JPG, PNG, BMP, TIFF et images extraites de vidéos MP4. Je peux extraire des images de votre vidéo si nécessaire.
Et si je n'ai pas encore de données étiquetées ?
C'est parfait. L'annotation est la première étape. Envoyez des images brutes et décrivez l'objet que vous souhaitez détecter.
Combien d'images sont nécessaires pour une bonne précision ?
Au minimum 200 par classe pour une détection basique. Plus de 500 par classe donnent un mAP de 85 à 92 %. Plus de 1000 donnent entre 90 et 96 %.
Pouvez-vous travailler avec des images médicales ou satellitaires ?
Oui. Envoyez d'abord une image d'exemple et je confirmerai la faisabilité avant votre commande.
Pouvez-vous déployer sur mon serveur au lieu de Jetson ?
Oui. Je déploie via FastAPI sur AWS, Google Cloud ou tout serveur Linux avec support GPU.