Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur logiciel
Ingénierie Big Data professionnelle pour une infrastructure évolutive et prête pour la production
Je propose des solutions big data pratiques, de bout en bout, allant de la planification de l’architecture à la mise en service et à l’optimisation en utilisant des outils standards de l’industrie. Chaque solution est adaptée à vos objectifs, votre infrastructure et vos besoins en charge de travail pour garantir performance, évolutivité et stabilité à long terme.
Services inclus :
Pourquoi les clients choisissent ce service :


Langue:
Anglais
•
Ourdou
Expertise technique:
Apache NiFi
•
Apache Spark
•
hadoop
•
Autres
Secteur:
Analyse de données
Traduction automatique
Quels types de projets de big data gérez-vous ?
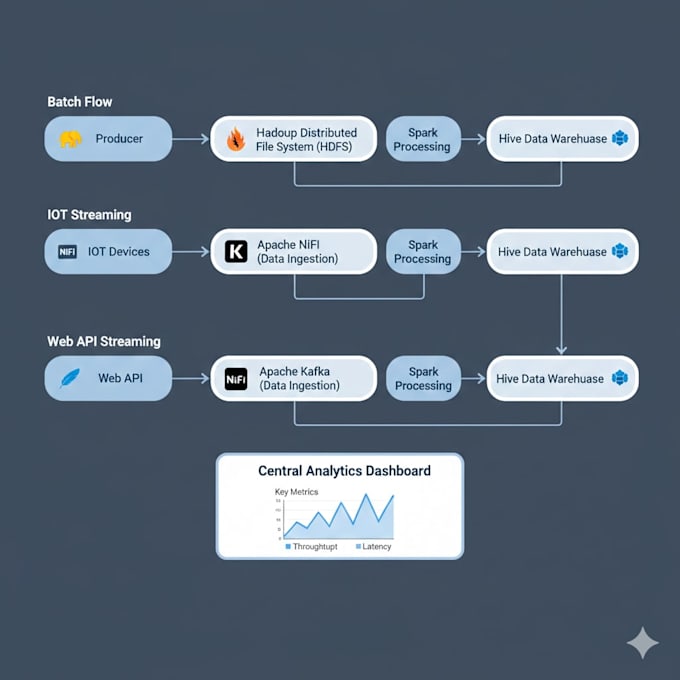
Je m'occupe de la configuration, du déploiement, de l'optimisation et du dépannage des environnements big data en utilisant Hadoop, Spark, Kafka, Hive, NiFi et d'autres outils liés — depuis de petits systèmes de preuve de concept jusqu'à des clusters de production.
Pouvez-vous mettre en place un cluster Hadoop ou Spark complet à partir de zéro ?
Oui. Je peux concevoir et déployer des clusters entièrement fonctionnels, y compris la configuration, l'optimisation des performances et la validation pour garantir leur stabilité.
Supportez-vous les pipelines de streaming de données en temps réel ?
Absolument. Je crée des pipelines de streaming basés sur Kafka et les intègre avec Spark ou NiFi pour un traitement efficace des données en temps réel.
Fournissez-vous de la documentation?
Oui. Une documentation claire est fournie pour vous aider à comprendre, gérer et maintenir votre système.
Comment commencer ?
Il vous suffit de partager vos besoins, les détails de votre infrastructure et vos objectifs — je vous proposerai le meilleur plan de mise en œuvre.