Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD





Traduction automatique
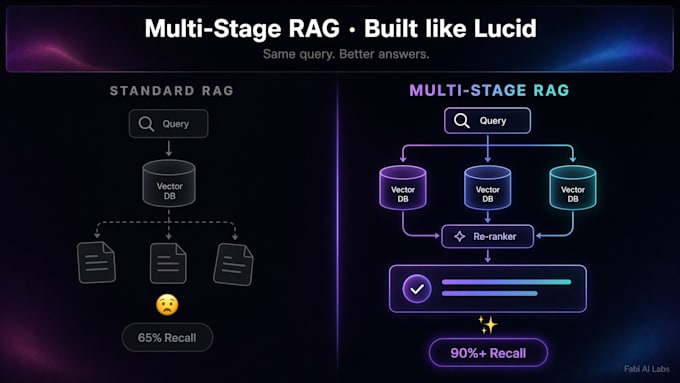
Le RAG standard atteint ses limites avec des questions complexes. Un bot à requête unique récupère des extraits mentionnant « remboursement » et manque de nuance — règles de tarification, clauses de dommages, politiques de commandes personnalisées.
Le RAG multi-étapes est différent. Il se décompose en sous-requêtes, recherche en parallèle, reclasse et synthétise. La précision passe de 65 % à plus de 90 %. Les réponses restent cohérentes. Les hallucinations diminuent.
CE QUE VOUS OBTENEZ :
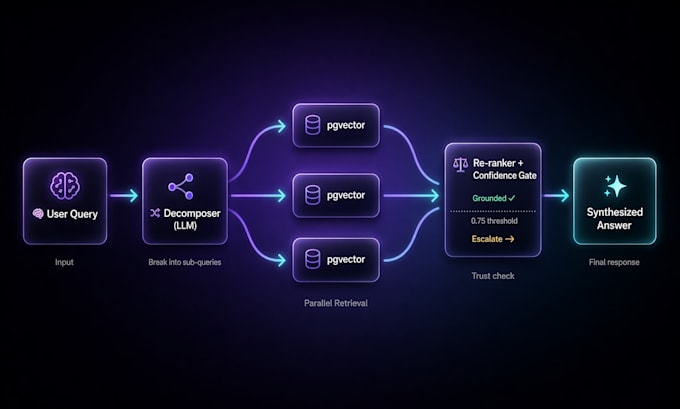
- Décomposition de requêtes (LLM divise les questions complexes en recherches ciblées)
- Embedding hypothétique HyDE pour la récupération
- Reclassement + score de confiance avant la génération de la réponse
- 4 safeguards : transfert humain, porte d’incertitude, pas de gaslighting, transparence
- Ensemble de tests d’évaluation personnalisé avec une qualité de récupération mesurable
- Tableau de bord d’administration pour le débogage des conversations et de la récupération (Premium)
TECHNOLOGIES : Python/TypeScript, Supabase pgvector, APIs OpenAI/Anthropic/Gemini, re-ranker personnalisé.
POURQUOI MULTI-ÉTAPES : le RAG à requête unique fonctionne pour les FAQ simples. Si votre bot gère la nuance de tarification ou des questions complexes — vous en avez besoin.
C’est ce que j’ai intégré dans Lucid. Même architecture pour votre domaine, adaptée à votre voix.
Envoyez-moi votre cas d’usage ainsi que 10 questions difficiles auxquelles votre bot actuel ne peut pas répondre. Je vous répondrai avec la portée.
AI Developer and Creator of Lucid
Langues
Traduction automatique
Traduction automatique
En quoi le RAG multi-étapes diffère-t-il du RAG basique ?
Le RAG basique effectue une recherche vectorielle par question. Pour les questions complexes, la précision en une seule recherche est d’environ 65 %. Le RAG multi-étapes décompose la question, recherche en parallèle, reclasse. La précision passe à plus de 90 %. Moins d’hallucinations, des réponses mieux ancrées.
Ce service coûtera-t-il plus cher que le RAG basique à grande échelle ?
Souvent moins. La décomposition utilise des modèles peu coûteux (Gemini Flash à environ 0,10 $ pour 1 million de tokens). La réponse finale utilise un appel à un modèle premium. Le RAG basique paie un premium pour chaque appel. À plus de 10 000 conversations par mois, le multi-étapes est souvent 30 à 50 % moins cher.
Que faire si mes documents sont désordonnés ou non structurés ?
Géré dans le cadre du scope. Je normalise les documents lors de l’ingestion — découpage par frontières sémantiques (pas de simples paragraphes), nettoyage des boilerplates, ajout de métadonnées pour la récupération par filtre. Les entrées désordonnées sont la norme, pas une exception.
Dois-je toujours fournir mes propres clés API ?
Oui — même politique que mon service Starter Bot. Vous possédez les comptes OpenAI / Anthropic / Gemini, payez directement sans marge, gardez le contrôle total. Je vous aide à choisir le mélange de modèles le plus rentable pour votre volume de trafic.