Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD


Traduction automatique
Arrêtez de gaspiller de l'argent en appels AI redondants !
La plupart des applications AI dépensent 40% à 80% de leur budget en appels redondants à LLM. Je suis là pour vous aider à arrêter cette fuite.
Je vais créer un cache sémantique prêt pour la production qui "se souvient" des requêtes passées et fournit des réponses instantanément, réduisant vos coûts et rendant votre application ultra-rapide.
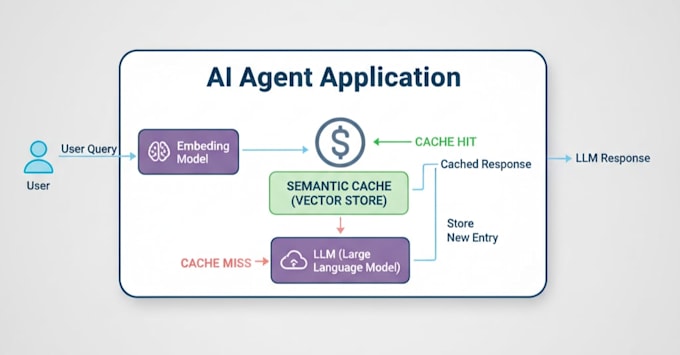
Qu'est-ce que le caching sémantique ?
Le caching standard est "bête" : il nécessite une correspondance mot à mot à 100%. Le caching sémantique est intelligent. Grâce aux embeddings vectoriels, votre système comprendra l'intention. Si l'utilisateur A demande "Quel temps fait-il ?" et l'utilisateur B demande "Quelle est la prévision ?", le système sait qu'il s'agit de la même question. Il fournit la réponse stockée instantanément sans appeler votre API.
️ Qu'est-ce qui est inclus dans ce service ?
Code, Scrape, Automate, FullStack Developer for Data and AI
Langues
Traduction automatique
Traduction automatique
Le caching ne va-t-il pas faire que l'IA donne des informations "anciennes" ou "fausses" ?
Pas si c'est bien fait. Nous mettons en place des "invalidation du cache" et des réglages de "Time-to-Live" (TTL). Si vos données changent fréquemment, nous pouvons faire expirer le cache toutes les heures. Si les données sont statiques, elles peuvent durer indéfiniment. Nous ajustons aussi le "seuil de similarité" pour que seules les questions vraiment similaires déclenchent un cache h
Combien d'argent vais-je réellement économiser ?
Cela dépend de votre "taux de hit du cache". Pour des bots de support client ou FAQ, les utilisateurs posent souvent des questions similaires, ce qui permet d'économiser entre 60 et 90 %. Pour des bots très créatifs ou avec des tâches uniques, l'économie tourne généralement autour de 20-30 %.
Mes données sont-elles sécurisées ?
Totalement. Le cache est hébergé sur votre infrastructure (ou votre base de données cloud préférée). Je ne stocke pas vos données sur mes propres serveurs.
Cela fonctionne-t-il avec n'importe quel LLM ?
Oui. Que vous utilisiez GPT-4o d'OpenAI, Google Gemini 1.5, Claude 3.5, ou même des modèles locaux comme Llama 3, la couche de caching se place devant l'API, la rendant indépendante du fournisseur.