Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Pakistan
3 commandes terminées
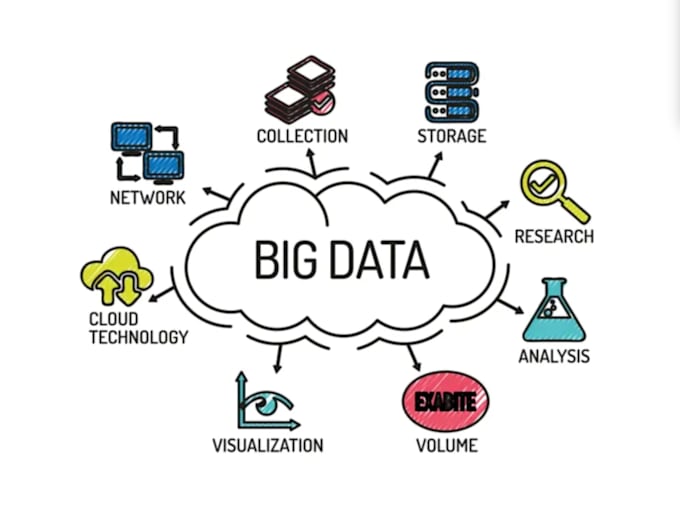
Ingénieur backend et IA : FastAPI, AWS, RAG, solutions LLM
Vous cherchez un ingénieur en données pour vous aider avec des projets big data, des pipelines ou de l’analyse?
Vous êtes au bon endroit. Je suis un ingénieur big data professionnel expérimenté en Hadoop, Spark, Kafka, Hive, PySpark, Scala et services cloud AWS.
Je réaliserai vos projets, construirai des pipelines de données, des jobs ETL, des clusters et des analyses en utilisant des outils standards de l’industrie et les meilleures pratiques.
Compétences pour cette offre de service en data :
Pourquoi choisir cette offre de service?
Je construirai des pipelines fiables, optimiserai des clusters et transformerai vos données brutes en analyses puissantes en utilisant Hadoop, Spark, Kafka, PySpark et AWS.
Tags associés : #BigData #DataEngineer #Spark #PySpark #Hadoop #Kafka #Airflow #AWS #ETL



Traduction automatique
Quelles technologies big data utilisez-vous dans vos projets d'ingénierie des données ?
J'utilise des outils de big data de premier plan tels que Hadoop, Spark, Kafka, Hive et PySpark. Ces technologies me permettent de concevoir des solutions d'ingénierie des données évolutives, de construire des pipelines efficaces et de traiter de grands ensembles de données pour l’analyse.
Pouvez-vous construire des pipelines de données de bout en bout avec Hadoop et Spark ?
Oui, je me spécialise dans la création de pipelines big data complets utilisant Hadoop et Spark. De l’ingestion des données à leur transformation et stockage, je crée des workflows ETL fiables adaptés à vos besoins professionnels.
Proposez-vous des solutions de streaming de données en temps réel avec Kafka ?
Absolument. Je développe des pipelines de streaming de données en temps réel avec Kafka, vous permettant de traiter et analyser efficacement les données en flux pour des cas d’utilisation comme la surveillance, l’analyse et les systèmes événementiels.
Quels types de services d’ingénierie des données proposez-vous ?
Je propose une large gamme de services d’ingénierie des données, notamment le développement ETL, le traitement big data, la configuration de clusters Hadoop, l’optimisation Spark, l’intégration Kafka et des solutions d’analyse de données.
Pouvez-vous optimiser des clusters Hadoop ou Spark existants ? Oui
Oui, je peux analyser et optimiser votre infrastructure Hadoop ou Spark existante pour améliorer la performance, réduire le temps de traitement et assurer une utilisation efficace des ressources.
Travaillez-vous avec PySpark pour le traitement big data ?
Oui, PySpark fait partie de mes compétences principales. Je l’utilise largement pour construire des workflows d’ingénierie des données évolutifs, effectuer des transformations de données et gérer des tâches de traitement big data à grande échelle.
Comment garantissez-vous la qualité et la fiabilité des données dans les pipelines ETL ?
Je suis les meilleures pratiques en ingénierie des données telles que les vérifications de validation, la journalisation, la gestion des erreurs et les tests pour assurer une haute qualité des données et des pipelines ETL fiables en utilisant des outils comme Spark, Hadoop et Kafka.
| (1) | ||
| (1) | ||
| (0) | ||
| (0) | ||
| (0) |
moozabh

Émirats Arabes Unis
The individual demonstrated exceptional technical ownership throughout the lifecycle of the Project. They are a high-trust contributor who consistently delivers "production-ready" results.!
50 $US-100 $US
Prix
3 jours
Durée

nicholasjohn10

États-Unis
Outstanding work on my big data project. The seller demonstrated deep knowledge of tools like Hadoop and Spark, delivered everything on time, and ensured accuracy throughout. Highly recommendations
Jusqu’à 50 $US
Prix
1 jour
Durée
| (1) | ||
| (1) | ||
| (0) | ||
| (0) | ||
| (0) |
moozabh
Émirats Arabes Unis
The individual demonstrated exceptional technical ownership throughout the lifecycle of the Project. They are a high-trust contributor who consistently delivers "production-ready" results.!
50 $US-100 $US
Prix
3 jours
Durée
nicholasjohn10
États-Unis
Outstanding work on my big data project. The seller demonstrated deep knowledge of tools like Hadoop and Spark, delivered everything on time, and ensured accuracy throughout. Highly recommendations
Jusqu’à 50 $US
Prix
1 jour
Durée