Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Développeur de produits numériques
Vous recherchez un professionnel en Data Scientist ou Ingénieur en apprentissage automatique ? Je crée des solutions d’IA sur mesure qui donnent des résultats. Avec une formation en informatique et développement full-stack, je propose une intégration complète, de l’entraînement des modèles à la création d’interfaces web fonctionnelles.
Mes services :
Outils & stack :
Pourquoi m’embaucher ?
Veuillez me contacter avant de passer commande pour discuter de vos besoins spécifiques !


Langage de programmation:
Python
•
R
•
SQL
Frameworks:
Scikit-learn
•
SimpleCV
•
keras
•
PyTorch
•
Panda
Outils:
Jupyter Notebook
•
opencv
•
tensorflow
•
Excel
•
Colab
Traduction automatique
Quels types d'images pouvez-vous classer ?
Pratiquement tous les domaines — images médicales (lésions cutanées, radiographies), photos de produits, faune, documents, images satellites, et plus encore. Si vous avez un ensemble de données et un schéma d’étiquetage, je peux créer un modèle pour cela.
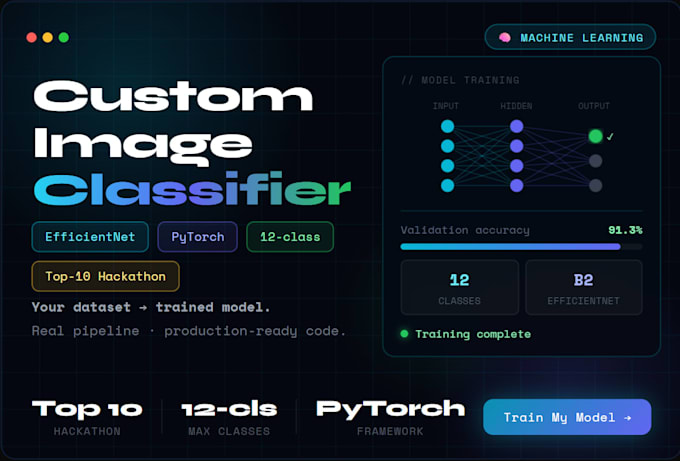
Combien de classes votre modèle peut-il gérer ?
J’ai travaillé avec des problèmes de classification jusqu’à 12 classes en production. Je peux gérer des configurations binaires ou multi-classes (plus de 20 classes) selon la taille et la complexité de votre dataset.
Quels frameworks et architectures utilisez-vous ?
PyTorch est mon cadre principal. Je travaille avec des architectures éprouvées comme EfficientNet, ResNet et ViT, en choisissant la meilleure en fonction de la taille de vos données et de vos exigences en termes de précision.
Que dois-je fournir ?
Votre dataset d’images étiquetées (organisé par dossiers de classes ou avec un fichier CSV d’étiquettes), le nombre de classes cibles, et toutes exigences spécifiques en termes de précision ou de déploiement que vous avez en tête.
Que faire si mon dataset est petit ?
Les petits datasets sont traités avec de l’apprentissage par transfert à partir de modèles pré-entraînés, combiné à des stratégies d’augmentation (miroirs, rotations, jitter de couleur, et techniques avancées comme CutMix/MixUp) pour maximiser la généralisation.
Que vais-je recevoir comme livrable ?
Un fichier de modèle entraîné (.pt / .onnx), un script d’inférence propre, un rapport d’entraînement avec les courbes de précision/perte et des métriques par classe, ainsi que des instructions pour effectuer des prédictions sur de nouvelles images.
Signerez-vous des NDA ou garderez-vous mes données confidentielles ?
Oui. Votre dataset et votre contexte professionnel restent confidentiels. Je suis prêt à signer un NDA si nécessaire avant que vous ne partagiez des données.