Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Architecte Laravel senior et spécialiste en automatisation AI
Le défi :
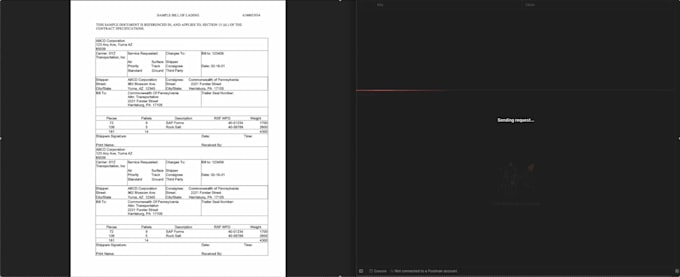
L'automatisation standard OCR pour le document "illisible" échoue souvent sur des scans inclinés ou des PDFs de faible résolution. La plupart des services nécessitent des modèles rigides qui se cassent dès qu’un expéditeur met à jour son formulaire.
La solution :
Analyse professionnelle basée sur l’IA. Ce service offre une extraction de données spécialisée qui transforme vos documents physiques ou numériques en fichiers JSON organisés.
Outils utilisés :
Ce que propose ce service :
NOTE : Pour les PDFs multipages, une page sera considérée comme un document et les documents doivent être imprimés NON manuscrits.
Prêt à nettoyer vos données ? Commençons



Technologie:
Python
Type d'information:
Autres
Technique:
Automatisé(e)
Traduction automatique
Dois-je fournir un modèle pour mes factures ou bons de livraison ?
Non. Mon moteur est indépendant de la mise en page. Que vous ayez différents transporteurs et styles de factures, le système identifie les champs clés (fournis par vous) sans besoin de modèle prédéfini pour chacun.
Que se passe-t-il si un document est extrêmement flou ou illisible ?
J’utilise des techniques avancées d’optimisation d’image pour clarifier les scans flous ou faibles en lumière. Cependant, si un document manque d’informations ou est totalement illisible même pour l’œil humain, je signalerai ce fichier et vous en informerai plutôt que de fournir des données "devinées" ou hallucinnées.
Mes données sont-elles sécurisées ?
Absolument. La confidentialité des données est une priorité. Je traite vos documents uniquement dans le but de l’extraction. Une fois les fichiers JSON vérifiés et la livraison confirmée, je peux supprimer toutes les images sources et données de mon environnement local sur demande.
Que vais-je recevoir exactement lors de la livraison ?
Vous recevrez un fichier JSON structuré (ou plusieurs fichiers, selon votre préférence) contenant tous les champs de données extraits (fournis par vous). Ces données sont propres et formatées pour être utilisées par vos systèmes internes ou équipes de données.
Pouvez-vous gérer des bordereaux d’expédition multi-pages ou des tableaux complexes ?
Oui. Contrairement aux outils OCR standards qui ont du mal avec des lignes s’étendant sur plusieurs pages, mon processus est précis à 99 % pour identifier de longs documents, garantissant que chaque ligne est capturée et correctement catégorisée dans le JSON final.