Exécutez modèles LLaMA localement sur votre propre matériel et débloquez une IA rapide et privée ! Je me spécialise dans le déploiement de LLaMA LLMs pour les débutants et les développeurs en utilisant llama.cpp, un moteur d'inférence léger en C/C++ qui permet une inférence locale haute performance. Vous bénéficierez d'une configuration complète sur Windows et Linux. pas de cloud, pas de frais récurrents, et un contrôle total sur vos modèles d'IA.
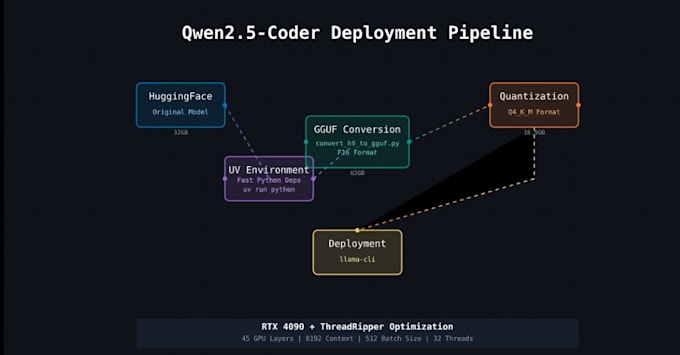
- Installation locale : Je vais installer et configurer les modèles LLaMA (2/3) ou compatibles GGUF les plus récents sur votre machine. Que vous soyez sous Windows, Linux ou Mac, je gère la configuration de l’environnement, les dépendances, et l’installation du build ou du binaire llama.cpp
- Optimisation GPU & CUDA : Avec le support CUDA de NVIDIA, je vais activer l’accélération GPU (et le multi-threading) pour accélérer l’inférence. En utilisant les optimisations de llama.cpp et la quantification des modèles (4-bit/8-bit), nous réduirons l’utilisation de la mémoire pour que même les grands modèles fonctionnent sans problème (Les modèles quantifiés sont beaucoup plus légers tout en conservant une bonne précision)
- Fine-tuning & données personnalisées : Dans le pack premium, je vais affiner votre modèle LLaMA sur votre propre jeu de données en utilisant LoRA adapters (LoRA nous permet d’adapter le modèle à vos besoins en entraînant uniquement les poids de l’adapter)