Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD




Traduction automatique
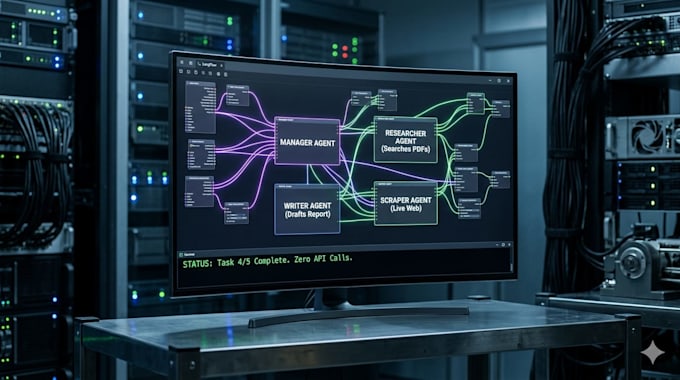
Je construis Infrastructure IA souveraine privée, locale et performante qui fonctionne sur votre propre matériel avec Zéro coût d’API.
En tant qu’architecte systèmes, je me spécialise dans le déploiement de grands modèles de langage (LLMs) et d’agents autonomes qui privilégient la souveraineté des données et la confidentialité. Que vous ayez besoin d’un assistant de recherche privé ou d’un flux de travail multi-agent complexe, je fournis un code propre, prêt pour la production, optimisé pour l’exécution locale.
Ce que je propose :
Le livrable : Chaque projet inclut le code source complet, un environnement Dockerisé pour une configuration en un clic, et une documentation professionnelle. Pas de gatekeeping, vous possédez le système que je construis.
Arrêtez de payer pour des tokens. Construisez votre forteresse.
Local Intelligence, Total Privacy, Expert AI Solutions
Langues
Traduction automatique
Traduction automatique
qu’est-ce que exactement «Sovereign Ai» et pourquoi en ai-je besoin ?
Sovereign AI signifie posséder votre intelligence plutôt que de la louer. Je construis des systèmes qui tournent sur votre matériel ou cloud privé. Aucune donnée ne quitte votre réseau, et vous ne payez aucun frais API mensuel. C’est un contrôle total sur vos données et votre avenir numérique.
Ai-je besoin d’un serveur à 10 000 $ pour faire tourner des LLM locaux ?
Non. En utilisant la quantification (GGUF/EXL2), j’optimise des modèles comme Llama 3 pour qu’ils fonctionnent sur du matériel grand public. Une RTX 3060/4060/5060 avec 8 Go de VRAM suffit pour un assistant privé à haute vitesse. Je me spécialise dans la mise en marche de modèles « lourds » sur des machines légères et efficaces.
L’IA peut-elle lire en toute sécurité mes documents privés d’entreprise ?
Oui. J’utilise RAG (Retrieval-Augmented Generation) pour créer une « base de données vectorielle » locale. L’IA recherche dans vos PDFs, CSVs ou fichiers SQL en temps réel. Vos données ne touchent jamais Internet et ne sont jamais utilisées pour entraîner des modèles publics. Elles restent 100 % privées.
Quelle est la différence entre RAG et Fine-Tuning ?
RAG ressemble à un « examen à livre ouvert » — l’IA recherche des faits dans vos données. Le Fine-Tuning, c’est comme une « chirurgie du cerveau » — il modifie la personnalité ou le jargon spécialisé de l’IA. RAG est idéal pour la précision ; le Fine-Tuning pour une voix unique. Je propose les deux pour une synergie totale du système.
C’est moins cher que de payer pour ChatGPT Plus ou des API ?
À long terme, absolument. Bien qu’il y ait un coût initial, votre coût par message devient de 0,00 $. Pour les entreprises à fort volume, une configuration souveraine s’autofinance généralement en 3 à 6 mois en éliminant les pièges d’abonnement récurrents et la dépendance aux fournisseurs.
Comment livrez-vous le produit final ?
Je fournis un « Conteneur Souverain » via Docker. Pas d’installations complexes ni de soucis de pilotes. Vous obtenez un script de configuration en un clic et un README professionnel. Lancez le script, et l’IA se déploie dans votre navigateur comme une application web privée et sécurisée.
Pouvez-vous m’aider pour la configuration initiale ?
Chaque package inclut un guide détaillé. Pour les niveaux Standard et Premium, j’offre une session à distance en tête-à-tête pour optimiser votre environnement en fonction de votre GPU et VRAM, afin d’assurer la meilleure performance possible en tokens par seconde.