Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
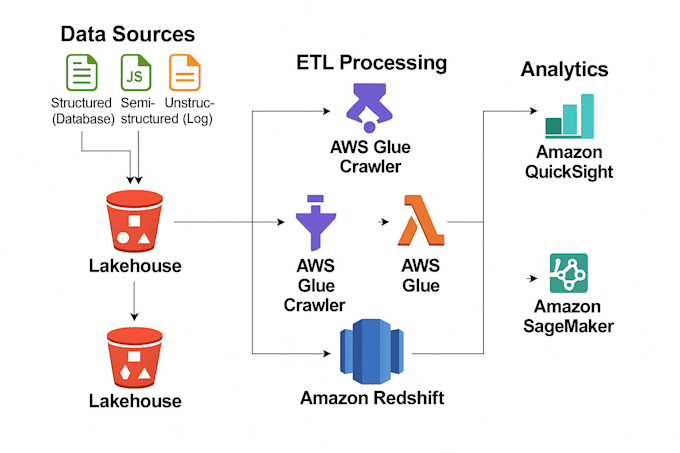
Je conçois et construis des pipelines de données évolutifs adaptés aux besoins de votre entreprise. En utilisant Python, PySpark, SQL et AWS, j’automatise l’ingestion, la transformation et le stockage des données pour fournir des données propres, fiables et prêtes pour l’analyse. Je réalise des vérifications de la qualité des données telles que la détection de valeurs manquantes, la suppression de doublons, la vérification du format et la validation du schéma pour garantir l’intégrité des données.
Je crée également des tableaux de bord interactifs et des rapports avec Amazon QuickSight et Tableau pour vous aider à suivre vos indicateurs clés de performance et à prendre des décisions basées sur les données facilement. Que vous ayez besoin de workflows ETL, de validation de données, de déploiement cloud ou de solutions de reporting, je fournis des systèmes optimisés et évolutifs.
Je privilégie une communication claire, la livraison à temps et un support continu pour faire évoluer votre infrastructure de données avec votre entreprise. Transformons vos données brutes en insights exploitables !