Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ukraine
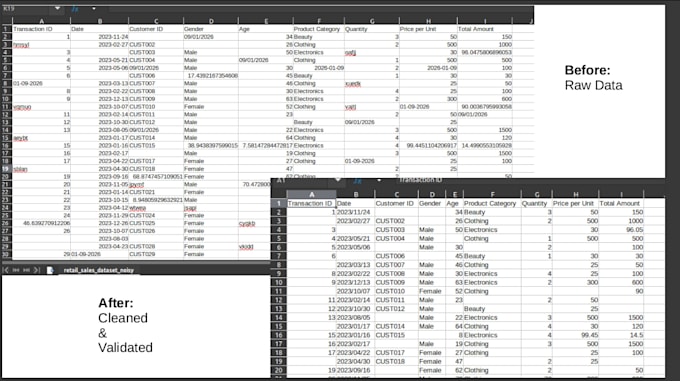
Databridge est un moteur de traitement de données local haute performance conçu pour transformer des données désordonnées et incohérentes en un entrepôt SQL structuré. Il automatise le processus de nettoyage des données, remplaçant des centaines d'heures de travail manuel par un seul outil sécurisé.
Principales fonctionnalités :
Automatisation en Python à son meilleur : Idéal pour les départements e-commerce, finance et marketing traitant des rapports fournisseurs fragmentés.


Technologie:
Python
•
Autres
Traduction automatique
Comment le moteur gère-t-il les en-têtes non standards ?
Il dispose d’un normaliseur robuste basé sur Regex. Tout en-tête comme __&&UsER+nAME🥰 est automatiquement nettoyé en user_name. Il utilise une correspondance floue pour trouver les bonnes colonnes même si leurs noms ou leur ordre varient entre les fichiers.
Quelles sont les règles spécifiques de transformation des données ?
Nous proposons une bibliothèque croissante de types : int, float, date, str, ainsi que des types spécialisés alpha (lettres uniquement) et identifiant. Tous les types utilisent une validation stricte et une coercition d’erreurs pour gérer en toute sécurité les données « sales ». De nouveaux types personnalisés sont constamment ajoutés au moteur.
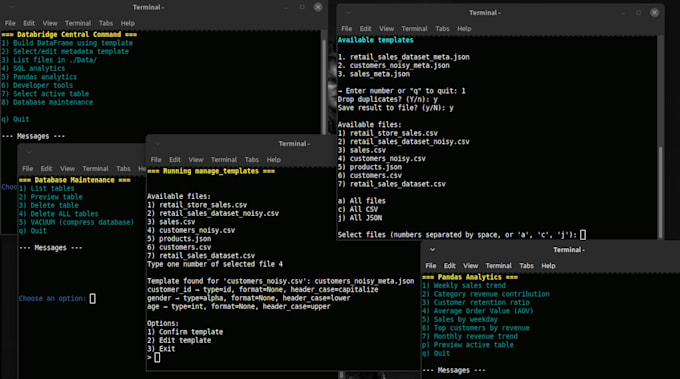
Comment fonctionnent vos modèles JSON ?
Les modèles agissent comme un contrat. Le moteur utilise regex pour trouver les colonnes cibles indépendamment de leurs noms ou de leur ordre. Il convertit ensuite strictement les données en vos types choisis (int, float, date) et les formate. Si une ligne manque de données ou échoue à la validation selon le modèle, elle est ignorée en toute sécurité.
Puis-je traiter plusieurs fichiers différents en même temps ?
Oui, dans le niveau Enterprise, le mode « Batch » vous permet de pointer le moteur vers un dossier. Il parcourra chaque fichier, ignorera les données non pertinentes selon votre modèle, et construira une base de données consolidée ligne par ligne.
Comment gérer la base de données de sortie ?
L’outil inclut un service de base de données. Vous pouvez basculer entre les tables actives, supprimer les anciens ensembles de données, et exécuter la commande VACUUM pour défragmenter le fichier SQLite et récupérer de l’espace disque.
Quelles sont les exigences du système?
Il s’agit d’un outil CLI basé sur Python. Il nécessite Python 3.9+ installé sur votre machine. Tout le traitement est local, ce qui signifie que la performance dépend de votre CPU/RAM, mais le moteur est optimisé pour des opérations batch à haute vitesse.