Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ingénieur en données cloud, BigQuery, Snowflake, dbt, Python, ETL
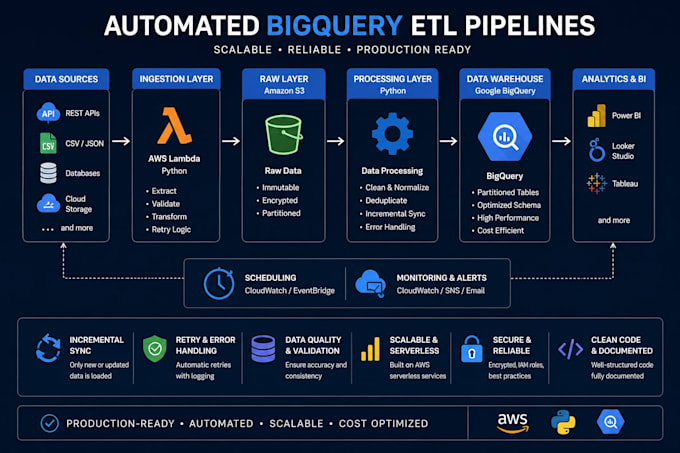
Construisez un pipeline ETL évolutif et prêt pour la production à partir d'API, CSV, JSON, bases de données ou stockage cloud directement dans Google BigQuery.
Je me spécialise dans les pipelines de données automatisés basés sur Python pour l’analyse, le reporting, Power BI, Looker Studio, Tableau et les plateformes de business intelligence.
Les services incluent :
Ingestion d'API vers BigQuery
Chargement incrémental de données
Remplissage historique
Normalisation JSON / CSV
Pipeline automatisé planifié
AWS Lambda / architecture sans serveur
Gestion des retries et des erreurs
Journalisation et surveillance
Déduplication des données
Tables BigQuery partitionnées
Architecture Raw Staging Curated
Structures d'entrepôt prêtes pour dbt
Technologies :
- Python
- BigQuery
- AWS Lambda
- S3 / GCS
- Airflow / Prefect
- dbt
- API REST
Cas d’usage typiques :
- Analyse e-commerce
- Reporting financier
- Tableaux de bord marketing
- Intégrations CRM
- Systèmes de reporting automatisés
Je privilégie les architectures évolutives, maintenables et prêtes pour la production plutôt que de simples scripts.
Veuillez me contacter avant de commander pour des projets personnalisés ou de grande envergure.
Les révisions n'incluent pas de changements majeurs de scope ou d’intégrations supplémentaires.





Traduction automatique
Supportez-vous de grands ensembles de données ?
Oui. Je conçois des pipelines évolutifs pour des millions de records et des charges de travail en production.
Pouvez-vous déployer sur AWS ?
Oui. Je peux déployer des architectures sans serveur utilisant Lambda, S3, Step Functions et CloudWatch.
Pouvez-vous optimiser les coûts BigQuery ?
Oui. J’utilise le partitionnement, le clustering, le traitement incrémental et des patterns de requêtes optimisés.
Quelle architecture privilégiez-vous pour votre pipeline de données ?
Je peux construire le pipeline en utilisant une architecture native AWS ou GCP selon votre infrastructure existante, votre budget et vos besoins en reporting. 1. API → Cloud Run / Cloud Function → GCS Raw → BigQuery 2. API → Lambda → S3 Raw → BigQuery Data Transfer Service → BigQuery
Pouvez-vous créer des pipelines ETL incrémentaux ?
Oui. Je privilégie fortement le traitement incrémental plutôt que les rechargements complets pour la scalabilité, la réduction des coûts BigQuery et une meilleure fiabilité.
Supportez-vous les transformations dbt ?
Oui. Je peux créer des modèles dbt pour le staging, le nettoyage, les joins, la logique métier et les tables d’analyses curatées.
Pouvez-vous travailler avec des entrepôts de données ou pipelines existants ?
Oui. Je peux améliorer, optimiser, déboguer ou étendre des environnements BigQuery, AWS ou ETL existants.
Pouvez-vous intégrer Power BI ou d’autres outils BI ?
Oui. Je peux préparer des datasets prêts pour l’analyse optimisés pour Power BI, Looker Studio, Tableau et l’analyse SQL.
Fournissez-vous une surveillance et une gestion des erreurs ?
Oui. Les pipelines en production incluent la journalisation, les retries, les alertes et la surveillance pour améliorer la fiabilité et la stabilité opérationnelle.
Pouvez-vous gérer des remplissages historiques et de grands datasets API ?
Oui. Je peux construire des pipelines pour la synchronisation historique, les API paginées et les datasets à grande échelle avec des stratégies de chargement optimisées.