Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Architecte en automatisation de données et spécialiste ETL
Infrastructure de données & analytique
Je construis des systèmes ETL/ELT qui transforment des données fragmentées en actifs fiables. Priorité : stabilité et évolutivité plutôt que des solutions temporaires.
Pourquoi cette architecture fonctionne :
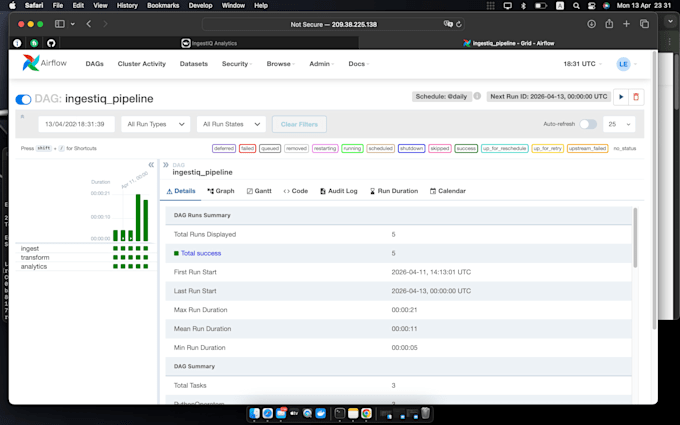
Conception modulaire : pipelines découplés des sources pour une montée en charge sécurisée.
Couche de cohérence : validation et gestion d’état pour une précision à 100 %.
Stockage bronze/argent : couches brutes/traitées pour optimiser la performance.
Déploiement indépendant : solutions Docker pour tout cloud ou installation locale.
Tableaux de bord personnalisés : interface Streamlit incluse dans chaque projet.
Collaboration & limites : je fournis des systèmes autonomes avec des limites claires :
Portée : couvre les sources et déploiements définis. Les nouvelles logiques ou intégrations sont des itérations séparées.
Fiabilité : gestion proactive des erreurs incluse. La surveillance 24/7 ou la maintenance du serveur sont des services séparés.
Propriété : documentation fournie pour une maintenance indépendante.
Pile technologique : Python, SQL, Airflow, Docker, Postgres, DuckDB.
Contactez-moi avant de commander pour aligner les besoins !

Destination Platform:
PostgreSQL
•
mySQL
•
Autres
Outils et plateformes:
Autres