Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Développeur de pipelines bioinformatiques
Avez-vous des données d'expression génique étiquetées et besoin
d'un classificateur d'apprentissage automatique pour prédire les sous-types de cancer
ou les résultats des patients ?
Je vais créer une pipeline de classification ML complète
adaptée à votre jeu de données génomiques.
CE QUE VOUS OBTENEZ :
- Prétraitement et normalisation des données
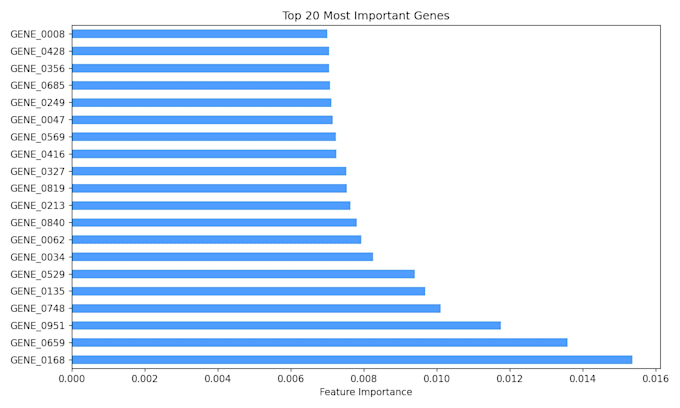
- Sélection de caractéristiques pour identifier les gènes les plus informatifs
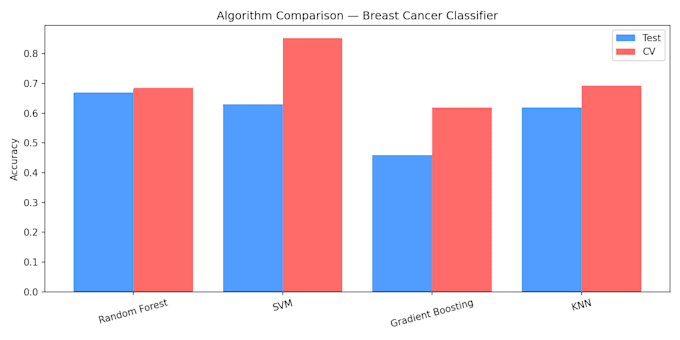
- Comparaison de plusieurs algorithmes (Random Forest, SVM,
Gradient Boosting, KNN)
- Évaluation de la précision par validation croisée
- Matrice de confusion et rapport de classification
- Visualisation de l'importance des caractéristiques
- Modèle prêt pour la production, sauvegardé
MON EXPÉRIENCE :
J'ai construit un classificateur de sous-types de cancer du sein à partir de données d'expression génique avec une précision de 85,2 % en validation croisée en utilisant SVM. J'ai classé 4 sous-types :
LuminalA, LuminalB, HER2, TripleNégatif.
Pipeline complet disponible sur GitHub.
CE QUE J'ATTENDS DE VOUS :
- Matrice d'expression génique (échantillons x gènes)
- Étiquettes de sous-type ou de résultat pour chaque échantillon
- Nombre de classes à prédire
- Gènes ou voies importantes connues
OUTILS : Python, scikit-learn, Pandas, numpy,
matplotlib, seaborn, joblib, Linux, Git



Expertise:
Classification
•
regroupement
•
Analyse prédictive
Langage de programmation:
Python
•
R
Frameworks:
Scikit-learn
•
Panda
APIs:
Autres
Outils:
Jupyter Notebook
•
RStudio