Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
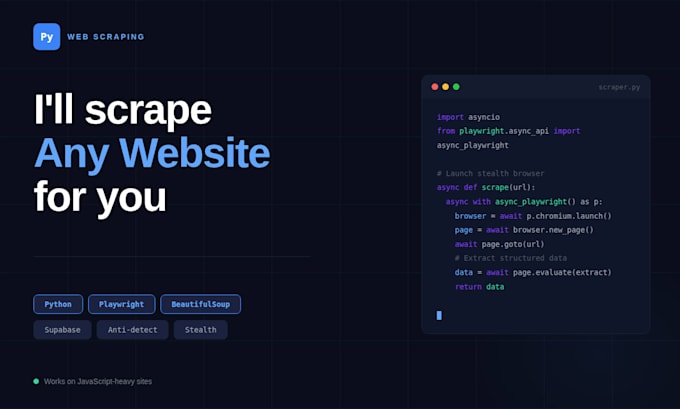
Développeur en web scraping et automatisation
Vous cherchez un scraper fiable qui fonctionne réellement ?
Je crée des scrapers personnalisés avec Python et Playwright capables de gérer n'importe quel site, y compris ceux avec beaucoup de JavaScript, la pagination et les pages nécessitant une connexion.
Ce que vous obtiendrez :
- Des données propres et structurées au format CSV ou JSON
- La gestion des sites dynamiques et des protections anti-bot
- Un scraper personnalisé pour votre site cible spécifique
- Des données livrées à temps, prêtes à l'emploi
Mon expérience :
J'ai créé IdolPulse, un agrégateur d'événements K-pop qui scrape simultanément 4 plateformes de billetterie ainsi que PTT, Naver et Soompi. Le scraper fonctionne quotidiennement et gère le contenu dynamique, la pagination et plusieurs langues.
Ce que je peux scraper :
- Listes de produits e-commerce et prix
- Publications et profils sur les réseaux sociaux
- Données d'actualités et d'événements
- Offres d'emploi et annuaires
- Tout site web dont vous avez besoin
Contactez-moi avant de commander si vous avez un site complexe, je confirmerai d'abord que c'est faisable.

Technologie:
Python
•
scrapy
•
sélénium
•
Beautiful Soup
•
Playwright
Technique:
Automatisé(e)
Traduction automatique
Pouvez-vous récupérer des sites Web qui nécessitent une connexion ?
Oui, je peux gérer les pages nécessitant une connexion en utilisant la gestion de session et les cookies.
Dans quel format les données seront-elles livrées ?
CSV ou JSON, selon votre préférence.
Que se passe-t-il si le site Web bloque le scraping ?
J'ai de l'expérience pour contourner les protections anti-bot courantes. Contactez-moi d'abord et je confirmerai si c'est faisable.