Certaines informations sont présentées en anglais.
À propos de moi
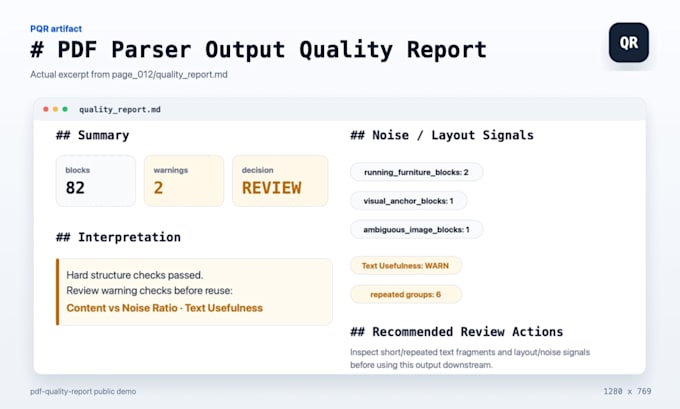
I work on PDF and document parsing cleanup with Python. I turn existing parser output from tools like Docling or PyMuPDF into reviewable JSON blocks, clean Markdown, JSONL chunk records, and short quality reports. I focus on traceability: source PDF, page number, bounding box, section context, and parser provenance where available. I am best suited for small pilots, sample reviews, and structured output preparation, not OCR guarantees, compliance ownership, or full RAG system builds.... Plus d’infos