Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
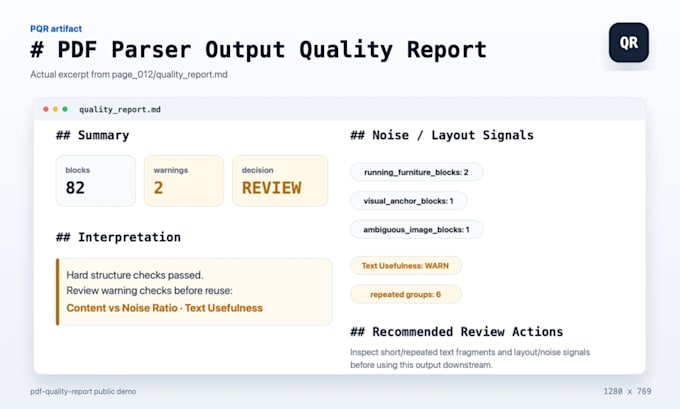
Révision de sortie PDF en JSON et Markdown
Le résultat de votre extraction PDF semble utilisable, mais vous avez besoin qu’il soit nettoyé et vérifié avant la revue, le nettoyage, la cartographie du schéma ou la préparation à l’ingestion RAG ?
Je passe en revue les sorties existantes de parseurs comme Docling, PyMuPDF, Unstructured ou d’outils similaires et crée :
Le travail commence en fonction de votre objectif : quels champs sont importants, quels ID ou références source doivent être conservés, et comment vous utiliserez la sortie en aval.
Ce dont j’ai besoin :
Ce que je ne couvre pas :

Technologie:
Python
Traduction automatique
Avec quels formats de parser pouvez-vous travailler ?
JSON de Docling est le plus adapté. PyMuPDF, Unstructured, LlamaParse ou un parser similaire produisant une sortie JSON/dictionnaire peut également fonctionner après une vérification d’échantillon rapide.
Fournissez-vous de l’OCR ou la reconstruction de tableaux ?
Pas par défaut. Ce service concerne la révision et le nettoyage de la sortie existante du parser. Les documents scannés, le nettoyage OCR et la reconstruction de tableaux complexes nécessitent un scope personnalisé après une vérification d’échantillon.
S’agit-il d’une construction de système RAG ?
Non. Je peux préparer des enregistrements JSON, Markdown ou JSONL révisables pour la préparation à l’ingestion, mais je ne construis pas le chatbot, le système de récupération, la base de données vectorielle ou l’évaluation de la qualité des réponses.