Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
À propos de moi,
Bonjour,
Je suis Data Scientist et ingénieur en apprentissage automatique junior avec une expérience concrète dans la création de modèles prédictifs pour divers domaines.
Je vais créer un modèle qui prévoit les résultats futurs en utilisant des techniques d'apprentissage automatique.
Le choix du modèle (Random Forest, régression logistique, XGBoost, etc.) dépendra de votre jeu de données et de l'objectif spécifique que vous souhaitez atteindre, que ce soit la classification, la régression ou la prévision.
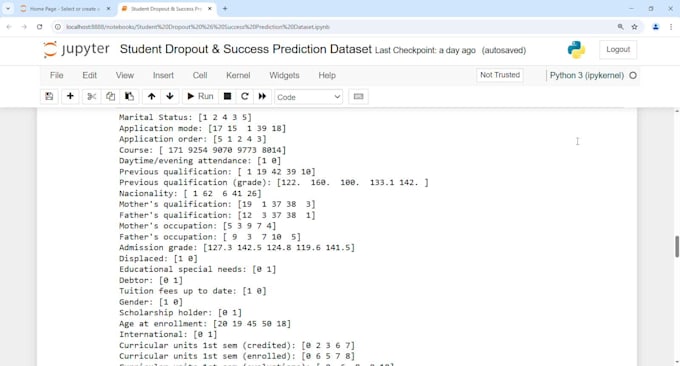
Un de mes projets réussis consiste à prédire le statut des étudiants (abandon, inscrit, diplômé) en utilisant 36 caractéristiques telles que les dossiers académiques, les données démographiques et financières avec Random Forest.
Ce que vous obtiendrez :
Si vous avez un projet impliquant la science des données ou des tâches d'apprentissage automatique, je suis là pour vous aider.
J'ai acquis une expérience précieuse sur des projets de niveau industriel. Je suis également très flexible et facile à travailler, et je m'engage à fournir de la valeur et des insights clairs.
Contactez-moi avant de passer commande pour que nous puissions trouver la meilleure solution pour vos données !



Langage de programmation:
Python
•
SQL
Frameworks:
Scikit-learn
•
Panda
•
Autres
APIs:
Autres
Outils:
Jupyter Notebook
Traduction automatique
De quel type de données avez-vous besoin de ma part pour commencer le projet ?
J'aurai besoin de votre jeu de données au format CSV ou Excel, accompagné d'une brève explication de ce que signifie chaque colonne et du résultat que vous souhaitez prévoir (par exemple, statut de l'étudiant, churn client, etc.). Plus vous fournissez de contexte, mieux je pourrai adapter le modèle à vos besoins.
Quels algorithmes d’apprentissage automatique utilisez-vous ?
Je choisis l'algorithme en fonction de votre jeu de données et de votre objectif. Parmi les modèles couramment utilisés, il y a Random Forest, régression logistique, arbres de décision, XGBoost, et d'autres. Si vous avez une préférence ou si vous avez besoin d'un modèle spécifique, faites-le moi savoir !