Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
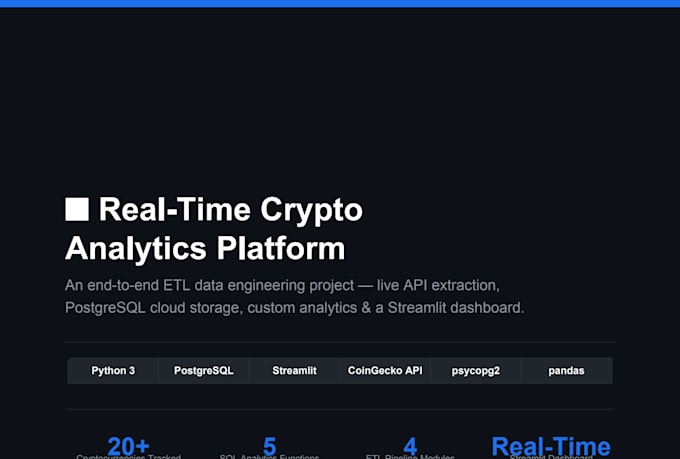
Je transforme les données en intelligence grâce au machine learning et deep learning
Vous cherchez des modèles ML précis, prêts pour la production, qui résolvent de vrais problèmes ? Vous êtes au bon endroit.
Je crée des solutions de machine learning et deep learning de bout en bout en Python, depuis des données brutes et désordonnées jusqu’à des modèles prédictifs entièrement fonctionnels et des pipelines de données.
CE QUE VOUS OBTENEZ
PROJETS RÉELS LIVRÉS
Code propre. Explications claires. Résultats concrets.
Contactez-moi avant de commander pour discuter de votre projet !

Langage de programmation:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
APIs:
Autres
Outils:
Jupyter Notebook
•
tensorflow
•
Excel
•
MLflow
•
Colab
Traduction automatique
Quels types de problèmes d'apprentissage automatique pouvez-vous résoudre ?
Je peux résoudre une large gamme de problèmes de ML supervisé et non supervisé, y compris la régression (prédiction de prix, prévision des ventes), la classification (détection de spam, prédiction de churn, etc.), le clustering et la détection d'anomalies. Si vous n'êtes pas sûr que votre problème corresponde, envoyez-moi un message et je vous dirai.
Dois-je fournir mon propre ensemble de données ?
Oui, idéalement vous devriez fournir votre dataset. Cependant, si vous n’en avez pas, je peux rechercher un dataset public pertinent (sur Kaggle, UCI ou via API ouvertes) pour votre problème. Plus vos données sont bonnes, meilleure sera la précision de votre modèle — partager des données réelles donne toujours les meilleurs résultats.
Dans quel format seront les livrables ?
Vous recevrez un notebook Jupyter propre (.ipynb) avec le code source complet, des explications bien commentées et des visualisations. Pour les packages Standard et Premium, vous recevrez également un rapport PDF ou une documentation du modèle. Tous les fichiers sont livrés dans une archive ZIP pour une organisation optimale et une utilisation facile.
Pouvez-vous garantir une précision spécifique du modèle ?
Aucun professionnel honnête en ML ne peut garantir une précision fixe, cela dépend fortement de la qualité, de la taille des données et de la complexité du problème. Ce que je garantis, c’est que j’appliquerai les meilleures techniques de prétraitement, d’ingénierie des caractéristiques et d’optimisation de modèle pour maximiser la performance. Je vous montrerai toujours la métrique d’évaluation.
Quelles bibliothèques et outils Python utilisez-vous ?
J’utilise principalement scikit-learn, Pandas, NumPy, Matplotlib et Seaborn pour le ML et l’analyse de données. Pour les pipelines et bases de données, j’utilise PostgreSQL, psycopg2 et MySQL. Pour les tableaux de bord, j’utilise Streamlit. Pour les tâches de deep learning, j’utilise TensorFlow/Keras. Toutes ces bibliothèques sont standard dans l’industrie et largement supportées.
Comprendrai-je le code même si je ne suis pas technique ?
Absolument. Chaque notebook est écrit avec des commentaires clairs, étape par étape, expliquant ce que chaque bloc de code fait et pourquoi. Pour les packages Standard et Premium, j’inclus aussi un résumé écrit des résultats en français simple, pour que vous compreniez les insights, pas seulement le code.
Pouvez-vous déployer le modèle pour que je puisse l’utiliser en direct ?
Oui, le déploiement cloud et l’intégration API sont inclus dans le package Premium. Je peux déployer votre modèle en tant qu’application web Streamlit ou point d’API REST, prêt à être utilisé en production. Si vous avez besoin d’un déploiement sur une plateforme spécifique (AWS, Render), contactez-moi avant de commander pour que nous puissions nous aligner sur la configuration.
Et si j’ai besoin d’un service personnalisé non listé dans vos packages ?
Pas de problème. Envoyez-moi vos exigences et je vous ferai une offre sur mesure adaptée à vos besoins précis. Que ce soit un dataset unique, un algorithme spécifique, un pipeline plus large ou un projet combiné ML + tableau de bord. Je suis heureux d’en discuter et de vous faire un devis.
Mes données sont-elles gardées confidentielles ?
100% oui. Vos données sont utilisées uniquement pour réaliser votre projet et ne sont jamais partagées, publiées ou réutilisées sous quelque forme que ce soit. Si vous souhaitez signer un accord de non-divulgation (NDA) avant de partager des données sensibles, je suis prêt à en signer un. La confidentialité et la sécurité de vos données sont prises très au sérieux à chaque étape.
Comment fonctionnent les révisions ?
La formule Basic inclut 1 révision, Standard en comprend 2, et Premium en comprend 3. Une révision couvre des ajustements dans le cadre du scope initial, comme modifier des paramètres de modèle, changer des visualisations ou corriger des bugs. Elle n’inclut pas l’ajout de fonctionnalités ou d’algorithmes totalement nouveaux au-delà du scope convenu.