Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Créez des applications web intelligentes avec l'IA et des solutions NLP pour les données
Titre : Organisation automatique de documents & Analyse NLP
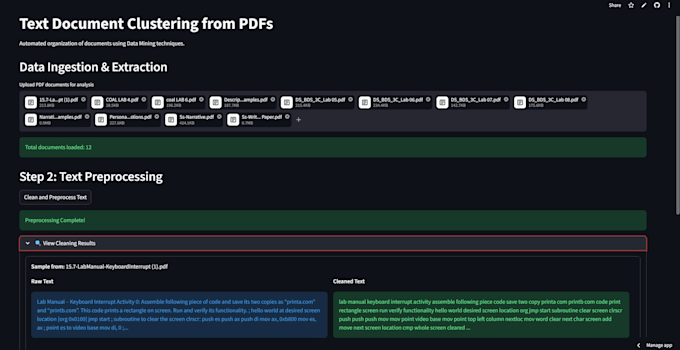
Bonjour ! Si vous êtes submergé par une montagne de documents PDF, je peux vous aider à les organiser en utilisant l'IA et le NLP.
Je ne me contente pas de regrouper les fichiers par mots-clés simples. J’utilise des embeddings sémantiques avancés pour comprendre le sens réel de votre texte, garantissant que vos documents sont classés de manière logique et précise.
Ce que je propose :
Je privilégie la précision et un code propre. Contactez-moi dès aujourd’hui pour discuter de votre projet !




Langage de programmation:
Python
Frameworks:
Scikit-learn
•
Panda
Outils:
Jupyter Notebook
•
Colab
Traduction automatique
Quels types de documents PDF pouvez-vous traiter ?
Je peux traiter presque tous les PDF basés sur du texte, y compris les articles de recherche, rapports d’entreprise et articles.
Pouvez-vous également traiter des fichiers Microsoft Word (.docx) ?
Oui, absolument ! Bien que la version standard de mon outil soit optimisée pour les PDF, je peux facilement modifier le pipeline d’ingestion pour gérer les fichiers .docx et .doc.
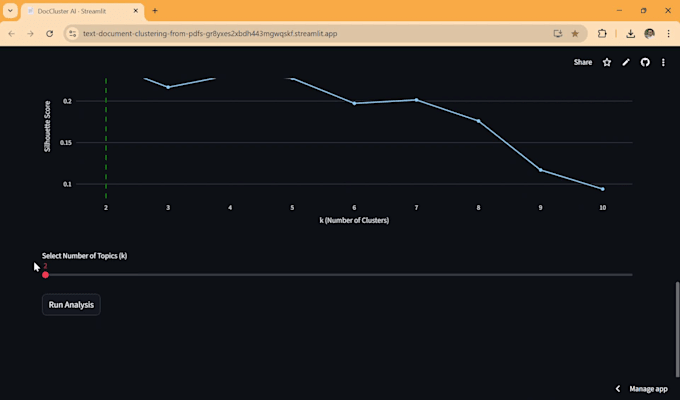
Comment garantissez-vous la précision des clusters ?
J’utilise une analyse du "Silhouette Score" pour déterminer mathématiquement le nombre de groupes le plus logique pour vos données. Cela garantit que les clusters ne sont pas aléatoires mais basés sur une densité sémantique réelle.
Dois-je fournir les "sujets" à l’avance ?
Non ! Il s’agit d’un apprentissage non supervisé, ce qui signifie que l’IA identifie elle-même les motifs et regroupe les documents.
Mes données sont-elles sécurisées ?
Absolument. Je traite vos données localement dans mon environnement de développement sécurisé. Une fois le projet livré et accepté, je supprime vos documents de mon système sauf si vous demandez le contraire.
Puis-je exécuter le tableau de bord Streamlit sur mon propre ordinateur ?
Oui. Si vous choisissez le package Premium, je fournis un fichier requirements.txt et une configuration .devcontainer, ce qui facilite l’exécution de l’application localement dans VS Code ou son déploiement dans le cloud.