Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Je ferai de la science des données ou de l'analyse de données
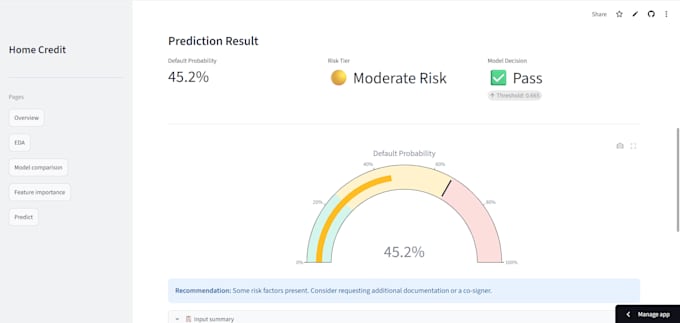
Démonstration en direct : credit-risk-prediction-better.streamlit.app
GitHub : github.com/Niqar/Credit-risk-prediction
Vous avez des données brutes mais vous ne savez pas comment en faire un modèle ML fonctionnel ? Je vais construire pour vous une pipeline d'apprentissage automatique complète, prête pour la production, du traitement des données désordonnées à un modèle qui fonctionne réellement.
Ce que je vais livrer :
Nettoyage des données et ingénierie des caractéristiques (gestion des valeurs manquantes, encodage, mise à l’échelle)
Entraînement du modèle LightGBM, XGBoost, Random Forest ou régression logistique
Optimisation des hyperparamètres avec Optuna pour de meilleures performances
Rapport d’évaluation complet (AUC, F1-score, précision, rappel, matrice de confusion)
Pipeline scikit-learn propre, reproductible et prêt à déployer
Notebook Jupyter + code Python documenté
Dépôt GitHub (sur demande)
Pourquoi travailler avec moi :
Je ne me contente pas d’entraîner un modèle et de le remettre. Je documente chaque étape pour que vous compreniez ce qui a été fait et pourquoi, et je m’assure que la pipeline est suffisamment propre pour être réutilisée ou étendue.
Consultez mon portfolio : credit-risk-prediction-better.streamlit.app
N’hésitez pas à m’envoyer un message avant de commander, je vérifierai votre dataset et confirmerai si je peux vous aider.



Langage de programmation:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
•
PyTorch
Outils:
Jupyter Notebook
•
opencv
•
tensorflow
•
Excel
•
Colab
Traduction automatique
Avec quel type de données travaillez-vous ?
Je travaille avec des données structurées/tabulaires — CSV, Excel ou exportations SQL. Cela couvre les problèmes de classification (fraude, churn, risque de crédit) et de régression (prédiction de prix, prévision des ventes). Pour les données d’image ou de texte, veuillez me contacter d’abord pour que je puisse évaluer la portée.
Que faire si mon jeu de données est désordonné ou comporte des valeurs manquantes ?
C’est tout à fait normal — gérer des données désordonnées fait partie de mon travail. Je vais les nettoyer, gérer les valeurs manquantes, encoder les caractéristiques catégoriques et mettre à l’échelle les numériques dans chaque package.
Quels modèles d’apprentissage automatique utilisez-vous ?
Principalement LightGBM, XGBoost, Forêt aléatoire et Régression logistique — en fonction de vos données et de votre objectif. Dans les packages Standard et Premium, j’entraîne et compare plusieurs modèles pour vous fournir le meilleur.
Pourrai-je réutiliser ou modifier le code moi-même ?
Oui. Tout le code est propre, commenté et structuré comme une pipeline scikit-learn — il est donc facile de le réentraîner avec de nouvelles données ou d’ajuster les paramètres. Je vous expliquerai aussi les parties clés pour que vous ne soyez pas laissé dans le doute.