Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Transformer les données en insights et les idées en solutions web efficaces
Vous cherchez un expert en ingénierie des données de haut niveau pour transformer vos défis liés aux big data en solutions fluides et évolutives ?
Bienvenue ! Je suis Nitin, un ingénieur en big data expérimenté avec plus de 3 ans d'expertise dans les technologies modernes d'ingénierie des données.
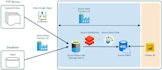
Je me spécialise dans la création de pipelines de données robustes, fiables et efficaces en utilisant Databricks, Apache Spark, Apache Airflow, Azure Data Factory (ADF) et des architectures événementielles avec Kafka. Que vous ayez besoin de workflows classiques ETL/ELT, de solutions avancées d'entreposage de données ou d'architectures Lakehouse innovantes avec Delta Lake, je suis là pour vous aider.
Ce que je propose :
Collaborons pour révéler la vraie valeur de vos données



Traduction automatique
Fournissez-vous un accompagnement après le projet ?
Oui, je propose un support après le projet et une assistance pour résoudre les problèmes afin d'assurer un fonctionnement fluide.
Quel est le délai de livraison ?
Le délai de livraison dépend de la complexité du projet, mais je m'efforce toujours de fournir un travail de qualité dans les plus brefs délais et de maintenir une communication claire.
Pouvez-vous aider à optimiser les performances ?
Absolument ! J’analyse et optimise vos workflows de données existants pour garantir des performances maximales et des coûts minimaux.
Dans quelles technologies vous spécialisez-vous ?
Databricks, Apache Spark, Apache Airflow, Azure Data Factory, Kafka, MQTT, Delta Lake, PySpark, SQL, et l'entreposage de données moderne.
Quels types de projets pouvez-vous gérer ?
De la construction de pipelines ETL/ELT évolutifs à la gestion de flux de données en temps réel et à la conception d'architectures d'entrepôts de données, je gère des projets de toutes tailles — des startups aux systèmes d'entreprise.


