Services professionnels d'ingénierie des données | Pipelines ETL | AWS | Databricks
Vous souhaitez créer des pipelines de données évolutifs et fiables pour votre entreprise ?
Je suis un ingénieur des données avec plus de 6 ans d'expérience dans la conception et l'optimisation de pipelines ETL utilisant les technologies cloud et big data modernes.
Ce que je peux faire pour vous :
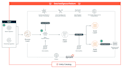
- Construire des pipelines ETL de bout en bout (Extraction, Transformation, Chargement)
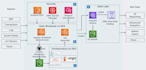
- Développer des jobs PySpark / Spark pour le traitement de données à grande échelle
- Concevoir des lacs de données sur AWS S3
- Créer des flux de travail avec Apache Airflow
- Mettre en œuvre des solutions Databricks pour l’analyse et le ML
- Optimiser les pipelines pour la performance et l’efficacité des coûts
- Intégrer des données provenant d’API, de bases de données et de fichiers (CSV, JSON, Parquet)
️ Stack technologique :
- AWS : S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
Pourquoi me choisir ?
- J’ai construit des pipelines traitant des ensembles de données de plusieurs téraoctets
- Forte orientation vers l’optimisation des performances
- Code propre, maintenable et prêt pour la production
- Communication rapide et livraison fiable
Exemples d’utilisation :
- Pipeline d’entrepôt de données
- Architecture de lac de données
- Workflows batch et planifiés
- Nettoyage et transformation de données
- Pipeline d’ingestion API vers S3