Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Nettoyage de données et entraînement de modèles
Je vais nettoyer votre dataset et le préparer pour l’analyse ou l’apprentissage automatique en utilisant Python. Si nécessaire, je peux également entraîner un modèle d’apprentissage automatique de base et fournir des résultats clairs, des métriques, des graphiques et un court rapport.
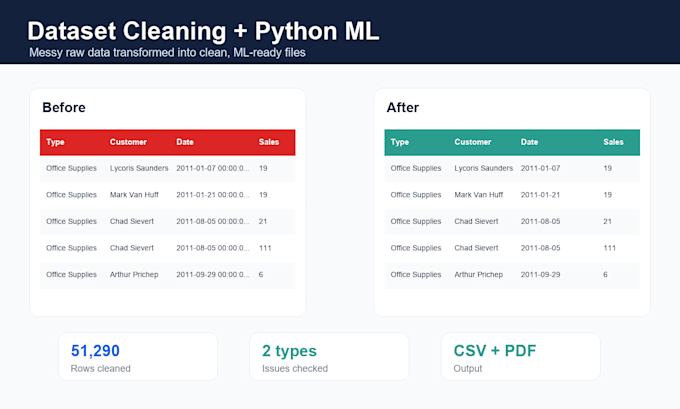
Je peux aider à résoudre les problèmes courants des datasets tels que les doublons, les valeurs manquantes, les formats incohérents, le texte sale, les formats de date mélangés, les nombres invalides, les étiquettes incorrectes et les catégories désordonnées.
Ce que je peux livrer :
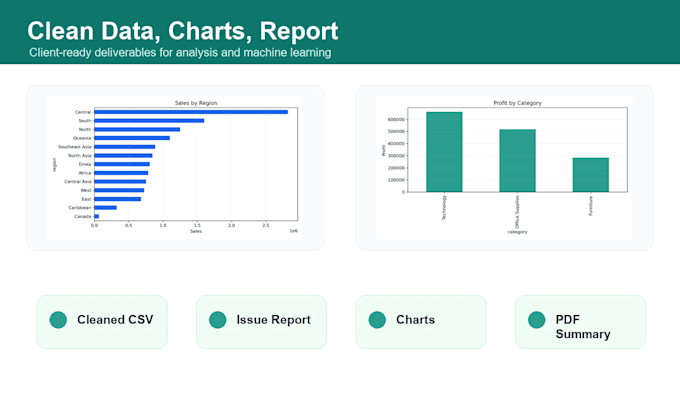
- Dataset nettoyé en CSV ou Excel
- Prétraitement des données
- Vérification des valeurs manquantes et des doublons
- Standardisation du texte, des dates, des nombres et des catégories
- Notebook ou script Python
- Entraînement de modèle ML de base
- Métriques d’évaluation du modèle
- Graphiques et court rapport
Types de modèles que je peux supporter :
- Classification
- Régression
- Modèles de prédiction
- Classification de texte
- Petite classification d’images si des étiquettes sont fournies
Outils que j’utilise :
Python, Pandas, scikit-learn, Jupyter Notebook, matplotlib, seaborn, PyTorch, OpenCV et YOLO pour les tâches d’image sélectionnées.
Veuillez m’envoyer un message avant de commander si votre dataset est volumineux, ne possède pas de colonne cible ou nécessite un entraînement en deep learning/GPU.
Note : Je ne garantis pas une précision spécifique. La performance du modèle dépend de la qualité, de la taille et des étiquettes de votre dataset.


Langage de programmation:
Python
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
Outils:
Jupyter Notebook
•
opencv
•
Excel
Traduction automatique
Pouvez-vous entraîner un modèle d’apprentissage automatique à partir de mon dataset ?
Oui, si votre dataset possède une colonne cible ou des étiquettes claires. Par exemple, la prédiction de prix nécessite une colonne prix, la prédiction de churn une colonne churn, et la classification d’images des dossiers d’images étiquetés ou des étiquettes.
Pouvez-vous uniquement nettoyer mon dataset ?
Oui. Le package Basic se concentre uniquement sur le nettoyage et la préparation du dataset.
Quels formats de fichiers acceptez-vous ?
Je peux travailler avec des fichiers CSV et Excel. Pour les datasets d’images ou de texte, veuillez m’envoyer un message avant de commander.
Garantissez-vous une haute précision ?
Non. La précision dépend de la qualité du dataset, du nombre d’échantillons, des caractéristiques, des étiquettes et du type de problème. Je fournirai des métriques d’évaluation honnêtes et des recommandations.
Pouvez-vous travailler avec de grands ensembles de données ?
Oui, mais veuillez me contacter d’abord. Les datasets volumineux peuvent nécessiter un tarif personnalisé et un délai de livraison plus long.
Pouvez-vous entraîner des modèles de deep learning ?
Pour de petits projets d’image ou de texte, oui, en fonction du dataset. Veuillez me contacter avant de commander des travaux de deep learning ou basés sur GPU.
Vais-je recevoir le code ?
Oui. Selon le package, je peux fournir un notebook Jupyter, un script Python, un dataset nettoyé, un fichier de modèle entraîné, et un rapport.
Pouvez-vous étiqueter mes données ?
Ce service n’inclut pas l’étiquetage manuel des données par défaut. Si vous avez besoin d’étiquetage, veuillez me contacter pour une offre personnalisée.