Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD





Traduction automatique
Vous en avez assez du traitement manuel des documents ? Laissez l'IA le faire en quelques secondes.
Je vais créer un pipeline personnalisé d'OCR et d'intelligence documentaire qui extrait, traite et analyse le texte provenant de PDFs, fichiers scannés, feuilles manuscrites et images, en fournissant un résultat propre, structuré et prêt pour la production.
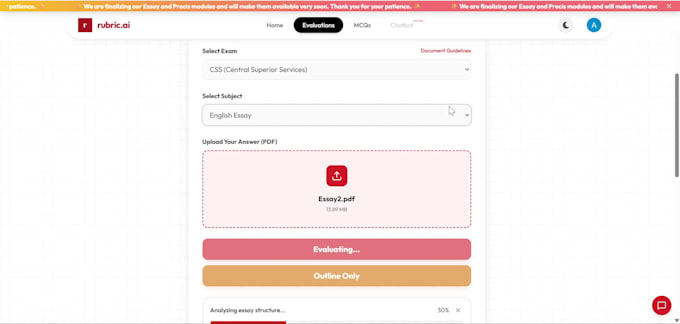
J'ai déjà construit et déployé de vrais systèmes d'OCR comme Rubric Ai incluant une plateforme d'évaluation d'examens alimentée par l'IA et un pipeline automatisé de traitement de factures, avec de vrais utilisateurs, pas des projets secondaires.
Ce que je construis : pipeline OCR pour PDFs, images et documents scannés, prétraitement pour les entrées bruyantes, manuscrites ou de faible qualité, analyse alimentée par LLM et extraction intelligente de texte, annotation automatisée et moteur d'évaluation, sortie JSON/CSV structurée prête à l'intégration, backend FastAPI et intégration à une base de données
Idéal pour : traitement de documents juridiques, médicaux et financiers, automatisation des examens, évaluations et notes, extraction de données de factures, reçus et contrats
Pourquoi me choisir : systèmes d'OCR déployés en production, pas seulement des tutoriels, gestion de l'écriture manuscrite, langues mixtes et scans de mauvaise qualité, code propre, source complet inclus, livraison à temps
Contactez-moi pour définir votre projet avant de commander.
Ai and Computer vision Solutions
Langues
Traduction automatique
Traduction automatique
Pouvez-vous créer un système personnalisé d'évaluation ou de notation de documents ?
Absolument. J'ai conçu des moteurs d'évaluation basés sur rubric et LLM qui notent et annotent les documents section par section. Que ce soit pour la notation d'examens, la revue de contrats ou la validation de formulaires, je peux créer un pipeline d'évaluation intelligent adapté à vos critères.
Quels types de documents votre pipeline OCR peut-il traiter ?
Mon pipeline OCR gère les PDFs, images scannées, documents photographiés et feuilles manuscrites. Il fonctionne avec des scans de faible qualité, du contenu en langues mixtes et des entrées bruyantes, avec prétraitement pour garantir une extraction précise et propre à chaque fois.
Pouvez-vous intégrer le système OCR à mon application ou base de données existante ?
Oui. Je crée des backends REST FastAPI qui se connectent directement à votre application. Je supporte MongoDB et PostgreSQL pour le stockage structuré des données et peux fournir une sortie JSON ou CSV propre compatible avec tout système en aval.
Qu'est-ce que l'intelligence documentaire et en quoi diffère-t-elle de l'OCR basique ?
L'OCR basique se limite à extraire du texte. L'intelligence documentaire va plus loin — utilisant des LLM pour analyser, classer, annoter et évaluer le contenu extrait selon des critères définis. C'est la différence entre lire un document et le comprendre réellement.
Fournissez-vous du code source et de la documentation ?
Oui, chaque livraison inclut le code source complet, des commentaires détaillés en ligne et une documentation d'installation pour que votre équipe puisse maintenir et étendre le système de manière autonome, sans dépendance envers moi.
Combien de temps faut-il pour construire un pipeline complet d'intelligence documentaire ?
Un pipeline d'extraction OCR basique prend environ 3 jours. Un système complet d'intelligence documentaire avec analyse LLM, moteur d'annotation, API et intégration à une base de données prend généralement entre 7 et 10 jours, selon la complexité. Contactez-moi d'abord pour obtenir un calendrier précis pour votre projet.