Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Projets Systems et ML C Python SQL, livrés à temps et optimisés
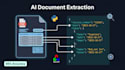
Vous êtes submergé par des PDFs, factures, formulaires ou images scannées nécessitant l'extraction de données ? Je crée des systèmes d'IA prêts pour la production qui le font automatiquement.
Je suis ingénieur en IA et vision par ordinateur avec une expérience pratique dans la création de pipelines de deep learning de bout en bout, depuis les données brutes jusqu'à une solution opérationnelle et déployable que vous pouvez réellement utiliser.
CE QUE JE CONSTRUIS
Traitement intelligent des documents (IDP)
Extraction de données structurées à partir de factures, reçus, contrats, formulaires médicaux, documents fiscaux et tout format PDF ou image personnalisé.
Pipeline OCR personnalisé
Au-delà de l'OCR de base, je construis des systèmes d'IA qui comprennent la mise en page, les tableaux, les cases à cocher et l'écriture manuscrite en utilisant TesseractOCR, PaddleOCR et le deep learning.
Vision par ordinateur et détection d'objets
Modèles YOLO (v8/v11) personnalisés, classification d'images, segmentation et suivi d'objets entraînés sur votre propre dataset.
Développement de modèles AI/ML
CNN, RNN, LSTM pour la classification, la régression, l'extraction de texte NLP et la prévision de séries temporelles.
Déploiement de modèles et API
API REST via FastAPI ou Flask, conteneurisation Docker, déploiement cloud (AWS, GCP), intégration avec votre frontend.
OUTILS & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Traduction automatique
Dois-je fournir des données d’entraînement ?
Cela dépend du projet. Pour des types de documents courants comme les factures ou reçus, je peux utiliser des modèles pré-entraînés et les adapter à votre format. Pour des documents très personnalisés ou avec des mises en page propriétaires, un jeu de données d'environ 50 à 200 exemples est idéal. Si vous n'en avez pas, je peux vous guider sur la façon de collecter et
Dans quel format les données extraites seront-elles livrées ?
Par défaut, je fournis une sortie structurée en JSON ou CSV. Si vous souhaitez que ce soit dans une base de données, un fichier Excel ou intégré à votre système via API, cela peut être organisé — indiquez-le simplement lors de votre message.
Quelle sera la précision de l'extraction ?
La précision dépend de la qualité et de la complexité du document. Pour des PDFs numériques et propres, elle atteint généralement 95 à 99 %. Pour des documents scannés ou manuscrits, 85 à 95 % sont réalistes. Je teste toujours sur vos documents réels avant livraison et inclue un rapport de performance.
Pouvez-vous travailler avec des documents dans des langues autres que l’anglais ?
Oui. PaddleOCR supporte plus de 80 langues et j'ai de l'expérience avec des pipelines multilingues. Veuillez mentionner votre langue lorsque vous me contactez.
Vais-je posséder le code ?
Oui, à 100 %. Tout le code source, les poids du modèle et la documentation vous appartiennent. Je ne conserve aucun droit sur ce que je construis pour vous.


