Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD



Traduction automatique
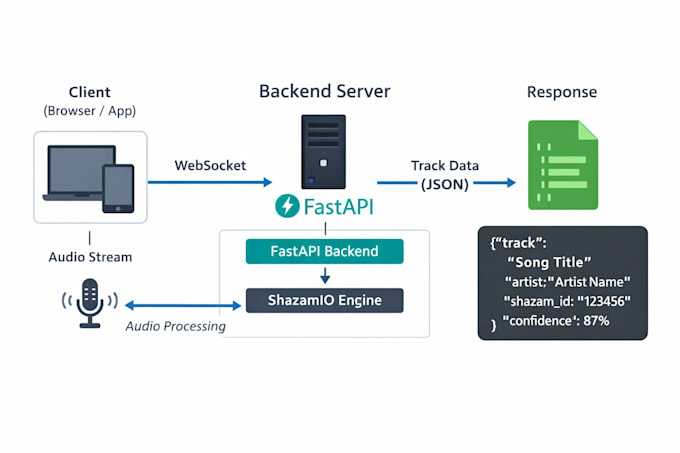
Obtenez un backend prêt pour la production qui identifie les chansons en temps réel à partir de l’audio du microphone en direct. Parfait pour les applications musicales, les outils de karaoké, les projets de recherche ou tout service nécessitant une reconnaissance fiable des chansons, le tout en Python, avec une configuration minimale.
Ce que vous recevez :
Entrée audio : PCM brut (compatible navigateur)
Sortie : événements JSON structurés
Les options de mise à niveau incluent un client de démonstration et un déploiement Dockerisé.
Chanson utilisée dans la vidéo de démonstration :
Chanson : Rameses B - ALL IN MY HEAD
Musique fournie par NoCopyrightSounds
Gratuit
I build AI powered revenue automations for ecommerce brands
Langues
Traduction automatique
Traduction automatique
Puis-je utiliser ce backend avec un client navigateur ?
Oui ! Le backend reçoit des octets PCM ou WAV bruts via WebSocket, vous pouvez donc diffuser de l’audio directement depuis un navigateur en utilisant MediaRecorder ou des bibliothèques comme WavTools.
Pourquoi utilise-t-on des morceaux de 10 secondes au lieu d’une fenêtre glissante continue ?
Les morceaux fixes de 10 secondes simplifient le système, le rendent plus fiable et plus facile à intégrer. Cela garantit que ShazamIO dispose de suffisamment d’audio pour une reconnaissance précise sans surcharger le serveur.
Puis-je changer la longueur du morceau ou la taille de la fenêtre ?
Techniquement oui, mais cela peut impacter la précision. 10 secondes sont recommandées pour le meilleur compromis entre vitesse et fiabilité de la reconnaissance.
Le backend fournit-il des paroles ou de l’audio en streaming ?
Non. Le service ne renvoie que des métadonnées de morceaux (titre, artiste, clé de morceau Shazam, score de confiance).
Quels formats audio sont supportés ?
Le backend attend du PCM/WAV brut. Le client gère l’enregistrement du microphone et la conversion avant l’envoi. FFmpeg est utilisé en interne pour toute conversion nécessaire en octets MP3 pour ShazamIO.
Cela peut-il fonctionner en production ?
Oui ! Le package Dockerisé fournit un backend prêt à déployer, adapté pour les applications, bots ou autres projets de reconnaissance audio en temps réel.
Et si ShazamIO ne reconnaît pas un morceau ?
Vous recevrez un événement JSON no_match. La reconnaissance dépend de la base de données de Shazam, donc certains morceaux peuvent ne pas être détectables.
Quelle est la rapidité de la détection ?
La reconnaissance est traitée en morceaux de 10 secondes, donc le délai est généralement d’environ la durée du morceau plus la latence réseau et le temps de traitement de ShazamIO.