Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD
Ce que nous faisons
Services clés
Processus
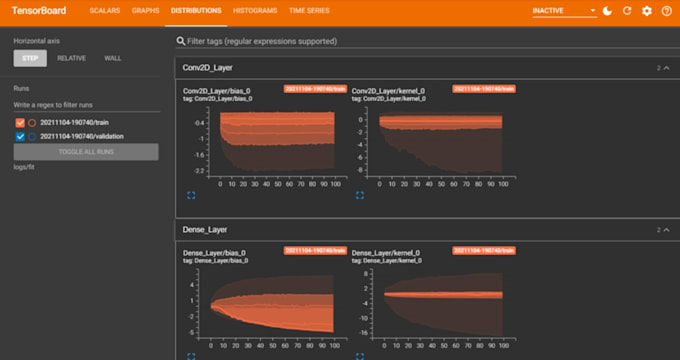
Pile technologique
PyTorch, TensorFlow, HF, scikit-learn, Optuna, MLflow, ONNX/TensorRT, Docker/FastAPI
Propriété
Vous détenez le code et les poids. Les coûts GPU cloud sont facturés au tarif du fournisseur. NDA/white-label disponible.
Pour commencer

Traduction automatique
Allez-vous signer un accord de confidentialité ?
Oui. Je suis à l’aise avec un NDA et/ou une clause de confidentialité mutuelle. Le travail en marque blanche est également possible.
Comment protégez-vous mes données ?
Accès avec le moins de privilèges possible, dépôts privés, stockage chiffré (lorsque le cloud est utilisé), et pas de partage avec des tiers. Je supprime les datasets et les artefacts sur demande ou 14 jours après la livraison.
Qui possède le modèle et le code ?
Vous. Transfert complet des poids entraînés, du code source et de la documentation. Note : les modèles de base / bibliothèques open source conservent leurs licences d’origine.
Quels sont les délais de livraison typiques ?
Basique : 7 jours, Standard : 14 jours, Premium : 28 jours. Des options très rapides sont disponibles dans Extras.
Qu’est-ce qui peut influencer les délais ?
La taille/qualité des données, l’étiquetage, le nombre d’essais HPO, les exigences de conformité, et la complexité du déploiement (cloud, mise à l’échelle, sécurité).
Pouvez-vous déployer le modèle pour une utilisation en production ?
Oui. La version Premium inclut le déploiement sur cloud ; la version Standard fournit une structure d’API. Je peux fournir une API REST Dockerisée avec vérifications de santé et documentation.
Quelles stacks supportez-vous ?
PyTorch/TensorFlow, Hugging Face, ONNX/TensorRT, FastAPI + Docker. Je m’intègre avec AWS/GCP/Azure, Vercel/DO, ou votre infrastructure locale.
Puis-je obtenir des exports pour mobile/edge ?
Oui, export du modèle en ONNX ; TFLite/Core ML sur demande, sous réserve de compatibilité du modèle.
Que comprend la documentation ?
Notes de configuration, commandes d’exécution, spécifications de l’endpoint, rapport d’évaluation, et une fiche modèle couvrant métriques, données, et limitations.
Assurez-vous la maintenance ?
Oui. Un entretien mensuel optionnel (corrections de bugs, petites mises à jour) est disponible en Extras ou dans un plan personnalisé.