Parcourir les catégories
Explorer
Fiverr Pro
Français
$
USD



Traduction automatique
Les wrappers ChatGPT génériques échouent à grande échelle. Vous avez besoin d’une intégration AI personnalisée ancrée dans vos données privées.
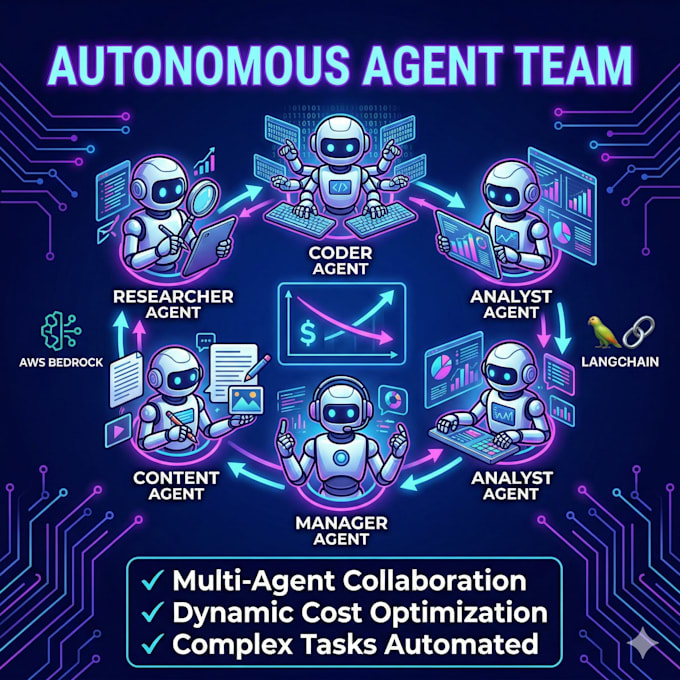
En tant qu’ingénieur AI Full Stack, je conçois des infrastructures avancées Python AI. Je contourne les scripts basiques pour construire des écosystèmes complexes LLM Integration. Que vous ayez besoin d’un backend SaaS ou d’un RAG pipeline sur mesure pour la recherche sémantique, je développe des agents AI personnalisés pour un raisonnement en plusieurs étapes.
Livrables architecturaux :
L’avantage de l’ingénierie :
Envoyez-moi vos besoins. Concevons votre système AI dès aujourd’hui.
Full Stack AI Engineer
Langues
Traduction automatique
Traduction automatique
Comment garantissez-vous la sécurité des données de mon entreprise lors de l’intégration de l’AI ?
Je conçois des backends Python sécurisés avec des bases vectorielles isolées (Milvus/PostgreSQL). Les données sont traitées via des APIs de niveau entreprise (AWS Bedrock, Anthropic) avec des politiques strictes de non-conservation, garantissant que vos données propriétaires ne soient jamais utilisées pour entraîner des modèles publics.
Pouvez-vous empêcher l’agent AI d’halluciner ou d’inventer des faits ?
Oui. Je conçois des pipelines RAG avancés utilisant la recherche sémantique et des bases de données vectorielles. Cela limite le LLM à synthétiser des réponses uniquement à partir de vos documents d’entreprise injectés, éliminant totalement les hallucinations et garantissant des résultats factuels.
Comment connectez-vous le backend AI personnalisé à mon logiciel existant ?
En tant qu’ingénieur Full Stack, je crée des endpoints FastAPI Python robustes qui relient sans problème vos nouveaux agents AI à n’importe quel frontend (Next.js, React) ou plateforme SaaS existante. Vous recevez des APIs entièrement documentées, prêtes pour la production et une mise en service immédiate.
Comment gérons-nous les coûts API lors de la montée en charge des systèmes multi-agent ?
J’implémente LiteLLM Server et OpenRouter dans votre architecture. Cela permet un routage dynamique des modèles — passant automatiquement de GPT-4 à Claude ou Llama selon la complexité de la tâche — maximisant la performance d’inférence tout en réduisant considérablement les coûts API.
Ai-je la propriété du code source et de l’infrastructure AI après livraison ?
Absolument. Je fournis un code Python entièrement documenté et une architecture système. Qu’il soit hébergé sur AWS Bedrock ou sur des serveurs cloud personnalisés, vous détenez 100 % de la propriété et du contrôle de votre pipeline AI propriétaire, de vos agents et de vos endpoints d’intégration.